Мы начинаем цикл кратких обзоров статей, использующих наши модели. Сегодня мы хотели бы познакомить вас с исследованием Полины Паничевой и Юлии Бадрызловой "Distributional Semantic Features in Russian Verbal Metaphor Identification" — http://www.dialog-21.ru/media/3935/panichevapvbadryzlovayug.pdf.
Основная идея выявления глагольной метафоры заключается в том, что при метафорическом использовании глагол, использованный в прямом значении, принадлежит к тому же семантическому кластеру, что и его аргументы. С другой стороны, глагол, использованный в метафорическом значении, выбивается из контекста и обладает более низким коэффициентом семантической близости со своими аргументами.
Чтобы проверить эту гипотезу, авторы создали датасет с примерами употребления глаголов в прямом и переносном значениях, извлекли глагольные аргументы при помощи синтаксического парсера MaltParser и вычислили семантическую близость между глаголом и различными типами его аргументов. Семантическая близость вычислялась на основе наших моделей на основе НКРЯ (ruscorpora_upos_skipgram_300_10_2017) и Википедии + НКРЯ (ruwikiruscorpora_upos_cbow_300_20_2017). Также авторы использовали оценку связности фрагмента предложения (Linear Semantic Coherence). На основе этих признаков SVM-классификатор определял, в прямом или метафорическом значении использован глагол в предложении. Точность классификации значительно отличается для разных глаголов.
В целом, авторы заключают, что наилучший набор признаков для классификации включает в себя и семантическую близость, и оценку связности, однако наибольший вклад в качество вносит оценка связности.
Основная идея выявления глагольной метафоры заключается в том, что при метафорическом использовании глагол, использованный в прямом значении, принадлежит к тому же семантическому кластеру, что и его аргументы. С другой стороны, глагол, использованный в метафорическом значении, выбивается из контекста и обладает более низким коэффициентом семантической близости со своими аргументами.
Чтобы проверить эту гипотезу, авторы создали датасет с примерами употребления глаголов в прямом и переносном значениях, извлекли глагольные аргументы при помощи синтаксического парсера MaltParser и вычислили семантическую близость между глаголом и различными типами его аргументов. Семантическая близость вычислялась на основе наших моделей на основе НКРЯ (ruscorpora_upos_skipgram_300_10_2017) и Википедии + НКРЯ (ruwikiruscorpora_upos_cbow_300_20_2017). Также авторы использовали оценку связности фрагмента предложения (Linear Semantic Coherence). На основе этих признаков SVM-классификатор определял, в прямом или метафорическом значении использован глагол в предложении. Точность классификации значительно отличается для разных глаголов.
В целом, авторы заключают, что наилучший набор признаков для классификации включает в себя и семантическую близость, и оценку связности, однако наибольший вклад в качество вносит оценка связности.
Активные пользователи RusVectōrēs могли заметить, что в последние месяцы мы что-то часто стали ломаться. Причина была в старом железе и вообще самопальном хостинге.
К счастью, сейчас всё это безобразие должно прекратиться: мы переехали на новый прекрасный сервер, за который спасибо компании Nlogic. Привет, стабильность!
( Но если вы заметите, что что-то работает не так, как раньше, то, пожалуйста, немедленно сигнализируйте нам
https://rusvectores.org/contacts/ )
К счастью, сейчас всё это безобразие должно прекратиться: мы переехали на новый прекрасный сервер, за который спасибо компании Nlogic. Привет, стабильность!
( Но если вы заметите, что что-то работает не так, как раньше, то, пожалуйста, немедленно сигнализируйте нам
https://rusvectores.org/contacts/ )
RusVectores
RusVectōrēs: семантические модели для русского языка
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
Мы продолжаем обзоры исследований, которые используют данные RusVectōrēs. Сегодня мы расскажем о статье Mrkšic et al. 2017 - "Semantic Specialization of Distributional Word Vector Spaces using Monolingual and Cross-Lingual Constraints", опубликованной коллективом авторов из Кембриджского университета, Техниона и корпорации Apple (http://www.aclweb.org/anthology/Q17-1022).
Авторы используют информацию из лексических баз данных, таких как WordNet и BabelNet, чтобы улучшить качество векторных семантических моделей. Алгоритм обогащения векторных моделей при помощи лексической информации, разработанный исследователями, называется Attract-Repel. В упрощенном виде этот алгоритм можно описать как изменение значений в классически обученных векторах слов в зависимости от того, являются ли два слова синонимами или антонимами. Если слова синонимичны, векторы их слов должны быть ближе друг к другу в векторном пространстве, если же слова антонимичны, то вектора их слова изменяются таким образом, чтобы быть дальше друг от друга.
Авторы тестируют свой алгоритм для нескольких языков, включая русский, используя для этого наши векторные модели. Стоит отметить, что именно модели для русского языка показали наилучшее качество при оценке на датасете SimLex-999. Помимо оценки моделей, авторы тестируют свой подход применительно к задаче Dialogue State Tracking — отслеживание состояния диалога. Модифицированные модели показывают значительное улучшение качества в сравнении со стандартными предсказательными моделями.
Авторы используют информацию из лексических баз данных, таких как WordNet и BabelNet, чтобы улучшить качество векторных семантических моделей. Алгоритм обогащения векторных моделей при помощи лексической информации, разработанный исследователями, называется Attract-Repel. В упрощенном виде этот алгоритм можно описать как изменение значений в классически обученных векторах слов в зависимости от того, являются ли два слова синонимами или антонимами. Если слова синонимичны, векторы их слов должны быть ближе друг к другу в векторном пространстве, если же слова антонимичны, то вектора их слова изменяются таким образом, чтобы быть дальше друг от друга.
Авторы тестируют свой алгоритм для нескольких языков, включая русский, используя для этого наши векторные модели. Стоит отметить, что именно модели для русского языка показали наилучшее качество при оценке на датасете SimLex-999. Помимо оценки моделей, авторы тестируют свой подход применительно к задаче Dialogue State Tracking — отслеживание состояния диалога. Модифицированные модели показывают значительное улучшение качества в сравнении со стандартными предсказательными моделями.
Сегодня ACM объявила лауреатов премии Тюринга ("нобелевка computer science") за 2018 год. Это отцы-основатели глубокого обучения нейронных сетей Джеффри Хинтон (Geoffrey Hinton), Йошуа Бенжио (Yoshua Bengio) и Ян ЛеКун (Yann LeCun).
Особенно приятно видеть в этом списке Бенжио. Ведь именно он в своей статье "A Neural Probabilistic Language Model" (2003) предложил выучивать распределенные репрезентации слов естественного языка.
http://www.jmlr.org/papers/v3/bengio03a.html
Чуть позже эти репрезентации стали называть word embeddings. Все модели RusVectōrēs основаны на этой идее (как и бОльшая часть всех современных NLP-алгоритмов).
https://www.acm.org/media-center/2019/march/turing-award-2018
Особенно приятно видеть в этом списке Бенжио. Ведь именно он в своей статье "A Neural Probabilistic Language Model" (2003) предложил выучивать распределенные репрезентации слов естественного языка.
http://www.jmlr.org/papers/v3/bengio03a.html
Чуть позже эти репрезентации стали называть word embeddings. Все модели RusVectōrēs основаны на этой идее (как и бОльшая часть всех современных NLP-алгоритмов).
https://www.acm.org/media-center/2019/march/turing-award-2018
www.acm.org
Fathers of the Deep Learning revolution receive 2018 ACM A.M. Turing Award
Yoshua Bengio, Geoffrey Hinton, and Yann LeCun, fathers of deep learning revolution, receive 2018 ACM A.M. Turing Award.
Анонс от нашего сайд-проекта RusNLP:
RusNLP обновлён публикациями за 2018 год (англоязычные статьи с "Диалога", AIST и AINL).
RusNLP - это веб-сервис для поиска по публикациям на российских NLP-конференциях. Мы не хотим соревноваться с Google Scholar или ArXiv Sanity Preserver: наш набор публикаций естественным образом ограничен, но зато тщательно и с любовью размечен по авторам, их аффилиациям, годам и так далее. Можно, например, искать все статьи про deep learning в обработке языка, опубликованные людьми из ИТМО в 2017-2018 годах. Или посмотреть, публиковался ли лингвист Александр Пиперски (лауреат премии "Просветитель" 2017 года) на каких-либо NLP-конференциях кроме "Диалога" (нет, не публиковался).
Также есть простейший поиск похожих статей (по TF/IDF), на случай если вы хотите поискать "что ещё публиковали в этом же духе".
В общем, такой who is who по российскому и околороссийскому компьютерно-лингвистическому сообществу.
Мы будем и дальше каждый год обновлять датасет новыми публикациями и вообще расширять сервис и добавлять новые фичи. Но там уже есть с чем поиграться, так что добро пожаловать, и будем рады любому фидбэку:
http://nlp.rusvectores.org/
RusNLP обновлён публикациями за 2018 год (англоязычные статьи с "Диалога", AIST и AINL).
RusNLP - это веб-сервис для поиска по публикациям на российских NLP-конференциях. Мы не хотим соревноваться с Google Scholar или ArXiv Sanity Preserver: наш набор публикаций естественным образом ограничен, но зато тщательно и с любовью размечен по авторам, их аффилиациям, годам и так далее. Можно, например, искать все статьи про deep learning в обработке языка, опубликованные людьми из ИТМО в 2017-2018 годах. Или посмотреть, публиковался ли лингвист Александр Пиперски (лауреат премии "Просветитель" 2017 года) на каких-либо NLP-конференциях кроме "Диалога" (нет, не публиковался).
Также есть простейший поиск похожих статей (по TF/IDF), на случай если вы хотите поискать "что ещё публиковали в этом же духе".
В общем, такой who is who по российскому и околороссийскому компьютерно-лингвистическому сообществу.
Мы будем и дальше каждый год обновлять датасет новыми публикациями и вообще расширять сервис и добавлять новые фичи. Но там уже есть с чем поиграться, так что добро пожаловать, и будем рады любому фидбэку:
http://nlp.rusvectores.org/
RusNLP
RusNLP: семантический поиск по научным статьям на российских конференциях в области natural language processing
На этой неделе мы представляем вам новый обзор исследования, использующего данные RusVectōrēs. Сегодня речь пойдет о статье "Extracting sentiment attitudes from analytical texts" Натальи Лукашевич и Николая Русначенко, представленной на конференции "Диалог" в 2018 году (http://www.dialog-21.ru/media/4317/loukachevitchnv_rusnachenkon.pdf).
Анализ тональности, или сентимент-анализ — определение эмоционального отношения автора текста к какому-либо феномену, описанному в этом тексте. Анализ тональности обычно применяется к документам, описывающим конкретный продукт (ресторан, товар и т.д.), или к сообщениям из социальных сетей (твитам, комментариям и т.д.). Авторы исследования применяют методы сентимент-анализа к более сложным текстам из корпуса RuSentRel. В этом корпусе содержатся статьи на тему международной политики, в которых размечены именованные сущности (страны, персоналии и т.д.).
Задача исследования -- классифицировать сентимент между двумя именованными сущностями (например, между сущностями "Россия" и "Турция") как положительный, отрицательный или нейтральный. Авторы тестируют значительное количество признаков для классификации, среди которых есть и семантическая близость между двумя сущностями, извлеченная из дистрибутивной семантической модели. Авторы исследования используют модель news_mystem_skipgram_1000_20_2015, предоставленную нашим веб-сервисом. Авторы не исследуют, какой из признаков вносит наибольший вклад в результаты классификации.
Наилучший результат, достигнутый в этом исследовании -- F-measure = 0.27 при использовании алгоритма Random Forest. В целом, данное исследование создаёт задел для других проектов в этой интереснейшей сфере.
Анализ тональности, или сентимент-анализ — определение эмоционального отношения автора текста к какому-либо феномену, описанному в этом тексте. Анализ тональности обычно применяется к документам, описывающим конкретный продукт (ресторан, товар и т.д.), или к сообщениям из социальных сетей (твитам, комментариям и т.д.). Авторы исследования применяют методы сентимент-анализа к более сложным текстам из корпуса RuSentRel. В этом корпусе содержатся статьи на тему международной политики, в которых размечены именованные сущности (страны, персоналии и т.д.).
Задача исследования -- классифицировать сентимент между двумя именованными сущностями (например, между сущностями "Россия" и "Турция") как положительный, отрицательный или нейтральный. Авторы тестируют значительное количество признаков для классификации, среди которых есть и семантическая близость между двумя сущностями, извлеченная из дистрибутивной семантической модели. Авторы исследования используют модель news_mystem_skipgram_1000_20_2015, предоставленную нашим веб-сервисом. Авторы не исследуют, какой из признаков вносит наибольший вклад в результаты классификации.
Наилучший результат, достигнутый в этом исследовании -- F-measure = 0.27 при использовании алгоритма Random Forest. В целом, данное исследование создаёт задел для других проектов в этой интереснейшей сфере.
В списках ближайших ассоциатов на RusVectōrēs теперь по умолчанию показываются только высокочастотные и среднечастотные слова.
Для изменения этого поведения появились чекбоксы с уровнями частотности: например, вы можете дополнительно включить показ низкочастотных ассоциатов. Или выключить даже среднечастотные слова и наслаждаться только хорошей, качественной высокочастотной лексикой. Изменение списка происходит динамически, без дополнительных запросов к серверу.
Это позволяет гибко регулировать баланс между качеством и полнотой результатов. И да, конечно, мы используем не абсолютные значения частот, а нормируем их на размеры обучающих корпусов.
https://rusvectores.org/associates/
Для изменения этого поведения появились чекбоксы с уровнями частотности: например, вы можете дополнительно включить показ низкочастотных ассоциатов. Или выключить даже среднечастотные слова и наслаждаться только хорошей, качественной высокочастотной лексикой. Изменение списка происходит динамически, без дополнительных запросов к серверу.
Это позволяет гибко регулировать баланс между качеством и полнотой результатов. И да, конечно, мы используем не абсолютные значения частот, а нормируем их на размеры обучающих корпусов.
https://rusvectores.org/associates/
RusVectores
RusVectōrēs: семантические модели для русского языка
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
fastText-модели на RusVectōrēs выложены для скачивания в нативном формате Gensim.
Библиотека Gensim активно обновляется. В частности, в последних релизах была существенно изменена логика работы с генерацией векторов для слов, отсутствующих в словаре (теперь она больше соответствует исходной реализации fastText от Facebook). Соответственно, немного изменился и формат хранения моделей.
TL:DR: если вы используете скачанные с нашего сайта fastText-модели, то скачайте их ещё раз прямо сейчас, их формат изменился. Также убедитесь, что вы используете свежий релиз Gensim (на сегодня это 3.7.2). Иначе корректная работа моделей не гарантируется, и мы умываем руки :)
Напоминаем, что процесс локальной работы с нашими моделями подробно описан в тьюториале: https://github.com/akutuzov/webvectors/blob/master/preprocessing/rusvectores_tutorial.ipynb
Библиотека Gensim активно обновляется. В частности, в последних релизах была существенно изменена логика работы с генерацией векторов для слов, отсутствующих в словаре (теперь она больше соответствует исходной реализации fastText от Facebook). Соответственно, немного изменился и формат хранения моделей.
TL:DR: если вы используете скачанные с нашего сайта fastText-модели, то скачайте их ещё раз прямо сейчас, их формат изменился. Также убедитесь, что вы используете свежий релиз Gensim (на сегодня это 3.7.2). Иначе корректная работа моделей не гарантируется, и мы умываем руки :)
Напоминаем, что процесс локальной работы с нашими моделями подробно описан в тьюториале: https://github.com/akutuzov/webvectors/blob/master/preprocessing/rusvectores_tutorial.ipynb
Сегодня мы представляем вам обзор статьи "Dark personalities on Facebook: harmful online behavior and language" (https://www.sciencedirect.com/science/article/pii/S0747563217305587), написанной коллективом авторов под руководством Ольги Боголюбовой. В этом исследовании авторы изучают взаимосвязь между негативными чертами личности, склонностью к вредоносному поведению в сети и языковыми характеристиками человека.
Для исследования при помощи специальной онлайн-платформы были опрошены более 6 тысяч русскоязычных пользователей социальной сети Фейсбук. Опрос включал в себя самооценку личностных черт, и вопросы об участии в кибербуллинге, троллинге и других негативных онлайн-практиках. Помимо этого, пользователи соглашались на обработку их текстовых записей в Фейсбуке.
Исследователей особенно интересовало, как взаимосвязаны черты личности из так называемой dark triad - нарциссизм, психопатия, склонность к манипуляциям - и лексические характеристики записей в соцсети. Для семантического анализа текстов авторы использовали нашу модель RusVectores на основе НКРЯ. Вектора слов, извлеченные из модели, были кластеризованы, и затем авторы подсчитали корреляцию между использованием слов из того или иного кластера и наличием одной из негативных черт личности.
Результатом исследования стало несколько интересных находок. Так, манипуляторы не склонны говорить о социальных взаимодействиях и эмпатии и не употребляют прилагательные, описывающие эмоции. Люди, заявившие о своей психопатии, говорят о базовых потребностях, таких как еда и финансы, а также о политике.
Основным недостатком исследования является тот факт, что все черты личности были описаны самими участниками, и неясно, насколько можно этому верить. Тем не менее, данное исследование очень интересно с точки зрения использования семантических моделей для анализа текстов и поведения в соцсетях.
Для исследования при помощи специальной онлайн-платформы были опрошены более 6 тысяч русскоязычных пользователей социальной сети Фейсбук. Опрос включал в себя самооценку личностных черт, и вопросы об участии в кибербуллинге, троллинге и других негативных онлайн-практиках. Помимо этого, пользователи соглашались на обработку их текстовых записей в Фейсбуке.
Исследователей особенно интересовало, как взаимосвязаны черты личности из так называемой dark triad - нарциссизм, психопатия, склонность к манипуляциям - и лексические характеристики записей в соцсети. Для семантического анализа текстов авторы использовали нашу модель RusVectores на основе НКРЯ. Вектора слов, извлеченные из модели, были кластеризованы, и затем авторы подсчитали корреляцию между использованием слов из того или иного кластера и наличием одной из негативных черт личности.
Результатом исследования стало несколько интересных находок. Так, манипуляторы не склонны говорить о социальных взаимодействиях и эмпатии и не употребляют прилагательные, описывающие эмоции. Люди, заявившие о своей психопатии, говорят о базовых потребностях, таких как еда и финансы, а также о политике.
Основным недостатком исследования является тот факт, что все черты личности были описаны самими участниками, и неясно, насколько можно этому верить. Тем не менее, данное исследование очень интересно с точки зрения использования семантических моделей для анализа текстов и поведения в соцсетях.
Sciencedirect
Dark personalities on Facebook: Harmful online behaviors and language
The goal of this paper was to assess the connection between dark personality traits and engagement in harmful online behaviors in a sample of Russian …
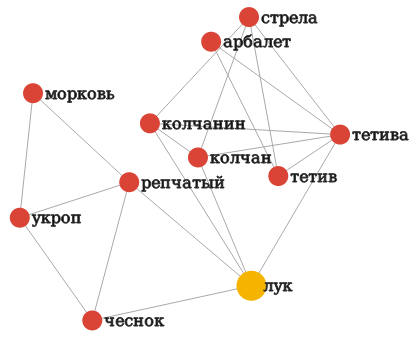
Vec2graph - визуализация связей слов в векторных моделях
Дружественный RusVectōrēs коллектив студентов магистратуры НИУ ВШЭ разработал python-библиотеку vec2graph. Она позволяет визуализировать эмбеддинги слов в виде динамических интерактивных графов и сохранять их в HTML-файлы, которые легко переносить или публиковать на сайтах. Библиотека очень проста в использовании и рассчитана на пользователей с минимальными навыками программирования. Уже послезавтра, 19 июля, она будет представлена на конференции AIST #aistconf, которая проходит в эти дни в Казани.
Принцип работы vec2graph заключается в том, что пользователь задаёт слово запроса, а библиотека визуализирует отношения этого слова с его ближайшими соседями в векторной модели (а также отношения соседей друг с другом). Каждое слово - это узел в графе, а веса на ребрах (и длина ребра) определяются косинусной близостью между словами. Можно задать определенный порог косинусной близости, ниже которого ребра между узлами визуализироваться не будут. Это помогает увидеть структуру семантического поля, заданного словом запроса и его соседями; также это полезно для анализа многозначных слов.
Vec2graph можно легко установить при помощи pip и сразу применить её к любой векторной модели, с которой умеет работать Gensim:
Например,
Мы надеемся, что vec2graph поможет вам в повседневных задачах, связанных с векторными представлениями слов. Кроме того, мы планируем добавить vec2graph-визуализации в интерфейс RusVectōrēs.
Дружественный RusVectōrēs коллектив студентов магистратуры НИУ ВШЭ разработал python-библиотеку vec2graph. Она позволяет визуализировать эмбеддинги слов в виде динамических интерактивных графов и сохранять их в HTML-файлы, которые легко переносить или публиковать на сайтах. Библиотека очень проста в использовании и рассчитана на пользователей с минимальными навыками программирования. Уже послезавтра, 19 июля, она будет представлена на конференции AIST #aistconf, которая проходит в эти дни в Казани.
Принцип работы vec2graph заключается в том, что пользователь задаёт слово запроса, а библиотека визуализирует отношения этого слова с его ближайшими соседями в векторной модели (а также отношения соседей друг с другом). Каждое слово - это узел в графе, а веса на ребрах (и длина ребра) определяются косинусной близостью между словами. Можно задать определенный порог косинусной близости, ниже которого ребра между узлами визуализироваться не будут. Это помогает увидеть структуру семантического поля, заданного словом запроса и его соседями; также это полезно для анализа многозначных слов.
Vec2graph можно легко установить при помощи pip и сразу применить её к любой векторной модели, с которой умеет работать Gensim:
pip install --upgrade vec2graph
from vec2graph import visualize
visualize(OUTPUT_DIR, MODEL, WORD)
где OUTPUT_DIR - это каталог для сохранения выходных файлов с графами, MODEL - векторная модель, загруженная через Gensim, WORD - слово запроса.Например,
visualize(graph_directory, my_model, лук, threshold=0.55). Результат показан на картинке https://raw.githubusercontent.com/lizaku/vec2graph/master/vec2graph/data/luk.pngМы надеемся, что vec2graph поможет вам в повседневных задачах, связанных с векторными представлениями слов. Кроме того, мы планируем добавить vec2graph-визуализации в интерфейс RusVectōrēs.
{kind=link}
Контекстуализированные модели ELMo на RusVectōrēs
Сервис RusVectōrēs предоставляет множество семантических векторных моделей, обученных при помощи старых добрых дистрибутивных алгоритмов Continuous Bag-of-Words, Continuous Skipgram и fastText. Эти модели достаточно хорошо отражают семантическое пространство русского языка и успешно используются в разнообразных практических задачах. Однако технологии не стоят на месте, и приходит время двигаться дальше.
Один из существенных недостатков всех перечисленных моделей - их "статичность". Что это значит? В word2vec, GloVe, fastText и других "статических" алгоритмах у каждого слова (последовательности символов) после обучения есть ровно один вектор. В каком бы контексте в ваших данных не встретилось это слово, предобученная модель всегда будет сопоставлять ему одну-единственную репрезентацию. Именно поэтому на RusVectōrēs вы можете просто ввести одно слово и получить его вектор.
Почему это проблема? Конечно же, из-за неоднозначности, которая пронизывает любой человеческий язык. Говорить о лексической семантике без контекста - всегда упрощение.
У слова "коса" в русском есть как минимум три не связанных друг с другом значения: прическа, часть берега и инструмент.
У слова "бор" два нарицательных значения (сосновый бор и химический элемент бор), а ведь ещё есть физик Нильс Бор.
Дистрибутивным моделям приходится "втискивать" все эти значения в один вектор, и это не всегда получается хорошо.
Решить эту проблему пытались как минимум с 2015 года (в том числе одной из первых попыток стал алгоритм AdaGram Сергея Бартунова и других). Сейчас господствующая парадигма в NLP такова: необходимо учитывать контекст не только при обучении моделей, но и при генерации векторов в практических приложениях. Ведь мы, люди, решаем, в каком именно значении употреблено слово, на основании других слов вокруг него (и общего контекста беседы, конечно).
То есть, на вход модели должно поступать не одно изолированное слово, а последовательность слов (например, предложение). Модель обрабатывает его целиком и генерирует для каждого слова его вектор, учитывая текущий контекст. Таким образом, в предложениях "Она заплела свою длинную косу" и "Возьми косу, коси траву!" для слова "косу" будут сгенерированы два разных вектора.
Подобные модели называются "контекстуализированными" (contextualized embeddings) и являются сейчас новым стандартом в автоматической обработке текста. Поэтому сегодня мы представляем две таких модели для русского языка, которые вы можете скачать вместе с нашими прошлыми моделями. Эти модели обучены при помощи алгоритма Embeddings from Language Models (ELMo), который описан в ныне уже классической статье Мэттью Петерса и других "Deep contextualized word representations" (NAACL-2018) и основан на двуслойной BiLSTM.
Обучающим корпусом послужила русская Википедия за декабрь 2018 года, объединенная с полным НКРЯ (всего около миллиарда слов). Доступны два варианта модели: обученная на сырых словах (ruwikiruscorpora_tokens_elmo_1024_2019) и на леммах (ruwikiruscorpora_lemmas_elmo_1024_2019). В целом, для ELMo лемматизация не так критична, как, например, для word2vec, поскольку на входе модель анализирует символы внутри слова, и похожие по форме токены в любом случае получат схожие репрезентации. Тем не менее, в наших экспериментах модель, обученная на леммах, всё же работала несколько лучше на некоторых задачах. Вы можете самостоятельно определить, что подходит именно вам.
Сервис RusVectōrēs предоставляет множество семантических векторных моделей, обученных при помощи старых добрых дистрибутивных алгоритмов Continuous Bag-of-Words, Continuous Skipgram и fastText. Эти модели достаточно хорошо отражают семантическое пространство русского языка и успешно используются в разнообразных практических задачах. Однако технологии не стоят на месте, и приходит время двигаться дальше.
Один из существенных недостатков всех перечисленных моделей - их "статичность". Что это значит? В word2vec, GloVe, fastText и других "статических" алгоритмах у каждого слова (последовательности символов) после обучения есть ровно один вектор. В каком бы контексте в ваших данных не встретилось это слово, предобученная модель всегда будет сопоставлять ему одну-единственную репрезентацию. Именно поэтому на RusVectōrēs вы можете просто ввести одно слово и получить его вектор.
Почему это проблема? Конечно же, из-за неоднозначности, которая пронизывает любой человеческий язык. Говорить о лексической семантике без контекста - всегда упрощение.
У слова "коса" в русском есть как минимум три не связанных друг с другом значения: прическа, часть берега и инструмент.
У слова "бор" два нарицательных значения (сосновый бор и химический элемент бор), а ведь ещё есть физик Нильс Бор.
Дистрибутивным моделям приходится "втискивать" все эти значения в один вектор, и это не всегда получается хорошо.
Решить эту проблему пытались как минимум с 2015 года (в том числе одной из первых попыток стал алгоритм AdaGram Сергея Бартунова и других). Сейчас господствующая парадигма в NLP такова: необходимо учитывать контекст не только при обучении моделей, но и при генерации векторов в практических приложениях. Ведь мы, люди, решаем, в каком именно значении употреблено слово, на основании других слов вокруг него (и общего контекста беседы, конечно).
То есть, на вход модели должно поступать не одно изолированное слово, а последовательность слов (например, предложение). Модель обрабатывает его целиком и генерирует для каждого слова его вектор, учитывая текущий контекст. Таким образом, в предложениях "Она заплела свою длинную косу" и "Возьми косу, коси траву!" для слова "косу" будут сгенерированы два разных вектора.
Подобные модели называются "контекстуализированными" (contextualized embeddings) и являются сейчас новым стандартом в автоматической обработке текста. Поэтому сегодня мы представляем две таких модели для русского языка, которые вы можете скачать вместе с нашими прошлыми моделями. Эти модели обучены при помощи алгоритма Embeddings from Language Models (ELMo), который описан в ныне уже классической статье Мэттью Петерса и других "Deep contextualized word representations" (NAACL-2018) и основан на двуслойной BiLSTM.
Обучающим корпусом послужила русская Википедия за декабрь 2018 года, объединенная с полным НКРЯ (всего около миллиарда слов). Доступны два варианта модели: обученная на сырых словах (ruwikiruscorpora_tokens_elmo_1024_2019) и на леммах (ruwikiruscorpora_lemmas_elmo_1024_2019). В целом, для ELMo лемматизация не так критична, как, например, для word2vec, поскольку на входе модель анализирует символы внутри слова, и похожие по форме токены в любом случае получат схожие репрезентации. Тем не менее, в наших экспериментах модель, обученная на леммах, всё же работала несколько лучше на некоторых задачах. Вы можете самостоятельно определить, что подходит именно вам.
RusVectores
RusVectōrēs: модели
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
Важно, что контекстуализированные модели устроены радикально иначе, чем "статические", и многие понятия из привычного мира word2vec теряют здесь смысл. Как уже было сказано, здесь нет "вектора слова X", есть только "вектор слова X в предложении Z". Отсутствует в чистом виде и "словарь модели": обработано будет любое слово, состоящее из стандартных символов. Соответственно, нет смысла и усложнять входные данные, добавляя к ним частеречные тэги (как сделано в большинстве старых моделей на RusVectōrēs). В большинстве случаев ELMo может самостоятельно разобраться, на какую часть речи больше похоже текущее слово в текущем предложении.
Ценой за обработку многозначности становятся повышенные требования к вычислительным ресурсам. Теперь модель - это уже не просто таблица векторов, а полноценная рекуррентная нейронная сеть, проходящая по предложениям на входе. Привычная многим библиотека Gensim не умеет работать с ELMo, поэтому мы подготовили минимальный код на Python и Tensorflow, достаточный для извлечения векторов из моделей.
Пока возможно только скачать модели с нашего сервера для локальной работы с ними, но в ближайшие несколько месяцев мы планируем интегрировать их в веб-интерфейс RusVectōrēs (если у вас есть идеи по этому поводу - пишите нам!). Будут и новые модели, обученные на более крупных корпусах. Также скоро ожидается jupyter notebook с тьюториалом по работе с ELMo.
Stay tuned!
Ценой за обработку многозначности становятся повышенные требования к вычислительным ресурсам. Теперь модель - это уже не просто таблица векторов, а полноценная рекуррентная нейронная сеть, проходящая по предложениям на входе. Привычная многим библиотека Gensim не умеет работать с ELMo, поэтому мы подготовили минимальный код на Python и Tensorflow, достаточный для извлечения векторов из моделей.
Пока возможно только скачать модели с нашего сервера для локальной работы с ними, но в ближайшие несколько месяцев мы планируем интегрировать их в веб-интерфейс RusVectōrēs (если у вас есть идеи по этому поводу - пишите нам!). Будут и новые модели, обученные на более крупных корпусах. Также скоро ожидается jupyter notebook с тьюториалом по работе с ELMo.
Stay tuned!
GitHub
GitHub - ltgoslo/simple_elmo: Simple library to work with pre-trained ELMo models in TensorFlow
Simple library to work with pre-trained ELMo models in TensorFlow - ltgoslo/simple_elmo
Продолжаем тему про ELMo-модели, которые мы выложили на днях. У многих мог возникнуть закономерный вопрос: а как оценить качество этих моделей? Стандартные способы из мира статических эмбеддингов (ранжирование пар слов по семантической близости или решение аналогий) тут не подходят, ведь они принимают на вход изолированные слова. Для ELMo же имеет смысл обработка только целых фраз. Поэтому ры решили использовать в качестве базовой оценки качество решения задачи word sense disambiguation (разрешение лексической неоднозначности в контексте). В конце концов, ведь в этом основной смысл контекстуализированных эмбеддингов!
Порядок действий тут очень простой. Допустим, имеется многозначное русское слово "лук". У нас есть 10 предложений, где это слово употреблено в значении "оружие", 10 в значении "овощ" и 5 в значении "внешний вид". Слово одно, но контексты вокруг него разные. Соответственно, ELMo (предположительно) сгенерирует существенно различные репрезентации для слова "лук" в существенно разных контекстах. Мы берём эти 25 эмбеддингов (10 как "оружие", 10 как "овощ" и 5 как "внешний вид") и обучаем простейший классификатор на логистической регрессии, используя вектора "лука" как входные данные, а три значения - как три метки или три класса. Разделяем данные на обучающий и тестовый сеты, обучаемся, оцениваем качество классификации. Чем оно лучше - тем больше в репрезентациях данной модели информации о том, в каком из многих значений слово "лук" употреблено в данном конкретном предложении. Метрика оценки - макро-усредненная F1 score (то есть, каждый смысл одинаково важен, даже если он редкий).
Размеченные данные мы взяли с соревнования RUSSE'18 (недавно почищенный датасет выложила Яндекс-Толока). Изначально он содержал 20 многозначных слов, но чтобы честным образом сравнить лемматизированные и не-лемматизированные модели, мы убрали слова "байка" и "гвоздика", у которых неоднозначность проявляется только в некоторых словоизменительных формах. Таким образом, осталось 18 слов, каждому из которых в среднем сопоставлено около 126 предложений (точнее, кусков текста) и метки соответствующих значений.
Наши модели мы сравнивали с двумя известными нам публичными ELMo для русского: HIT-SCIR ElmoForManyLangs и DeepPavlov. Также на всякий случай мы сравнились с традиционными статическими word2vec-эмбеддингами (в этом случае на вход классификатору подавался средний вектор всех слов в предложении). Итоги такие (чем выше F1 score, тем лучше модель):
- word2vec (lemmas): 0.85
- ElmoForManyLangs: 0.74
- DeepPavlov: 0.88
- RusVectores (tokens): 0.88
- RusVectores (lemmas): 0.91
Как и предполагалось, ELMo существенно лучше в разрешении лексической неоднозначности, чем статические эмбеддинги. Правда, это не касается ElmoForManyLangs, обученной коллегами из Харбина. Их модели (в том числе для русского) использовали очень небольшой корпус, и, скорее всего, просто не успели в достаточной степени выучить семантику. Поэтому эта модель проигрывает даже word2vec (что не помешало этим же моделям выиграть соревнование по синтаксическому парсингу CONLL2018).
По сравнению с ELMo от DeepPavlov, наша модель на токенах находится на том же уровне, а модель на леммах слегка обгоняет. При этом модели с RusVectōrēs в два раза легче, и, соответственно, быстрее. Причина в том, что мы использовали размерность LSTM 2048, вместо значения по умолчанию 4096. Как мы видим, это не приводит к ухудшению качества (по крайней мере, на задаче разрешения неоднозначности).
На этом мы заканчиваем сегодняшний рассказ про ELMo и желаем вам интересных экспериментов! В следующих постах мы расскажем о других аспектах наших новых контекстуализированных эмбеддингов. Пока!
Порядок действий тут очень простой. Допустим, имеется многозначное русское слово "лук". У нас есть 10 предложений, где это слово употреблено в значении "оружие", 10 в значении "овощ" и 5 в значении "внешний вид". Слово одно, но контексты вокруг него разные. Соответственно, ELMo (предположительно) сгенерирует существенно различные репрезентации для слова "лук" в существенно разных контекстах. Мы берём эти 25 эмбеддингов (10 как "оружие", 10 как "овощ" и 5 как "внешний вид") и обучаем простейший классификатор на логистической регрессии, используя вектора "лука" как входные данные, а три значения - как три метки или три класса. Разделяем данные на обучающий и тестовый сеты, обучаемся, оцениваем качество классификации. Чем оно лучше - тем больше в репрезентациях данной модели информации о том, в каком из многих значений слово "лук" употреблено в данном конкретном предложении. Метрика оценки - макро-усредненная F1 score (то есть, каждый смысл одинаково важен, даже если он редкий).
Размеченные данные мы взяли с соревнования RUSSE'18 (недавно почищенный датасет выложила Яндекс-Толока). Изначально он содержал 20 многозначных слов, но чтобы честным образом сравнить лемматизированные и не-лемматизированные модели, мы убрали слова "байка" и "гвоздика", у которых неоднозначность проявляется только в некоторых словоизменительных формах. Таким образом, осталось 18 слов, каждому из которых в среднем сопоставлено около 126 предложений (точнее, кусков текста) и метки соответствующих значений.
Наши модели мы сравнивали с двумя известными нам публичными ELMo для русского: HIT-SCIR ElmoForManyLangs и DeepPavlov. Также на всякий случай мы сравнились с традиционными статическими word2vec-эмбеддингами (в этом случае на вход классификатору подавался средний вектор всех слов в предложении). Итоги такие (чем выше F1 score, тем лучше модель):
- word2vec (lemmas): 0.85
- ElmoForManyLangs: 0.74
- DeepPavlov: 0.88
- RusVectores (tokens): 0.88
- RusVectores (lemmas): 0.91
Как и предполагалось, ELMo существенно лучше в разрешении лексической неоднозначности, чем статические эмбеддинги. Правда, это не касается ElmoForManyLangs, обученной коллегами из Харбина. Их модели (в том числе для русского) использовали очень небольшой корпус, и, скорее всего, просто не успели в достаточной степени выучить семантику. Поэтому эта модель проигрывает даже word2vec (что не помешало этим же моделям выиграть соревнование по синтаксическому парсингу CONLL2018).
По сравнению с ELMo от DeepPavlov, наша модель на токенах находится на том же уровне, а модель на леммах слегка обгоняет. При этом модели с RusVectōrēs в два раза легче, и, соответственно, быстрее. Причина в том, что мы использовали размерность LSTM 2048, вместо значения по умолчанию 4096. Как мы видим, это не приводит к ухудшению качества (по крайней мере, на задаче разрешения неоднозначности).
На этом мы заканчиваем сегодняшний рассказ про ELMo и желаем вам интересных экспериментов! В следующих постах мы расскажем о других аспектах наших новых контекстуализированных эмбеддингов. Пока!
Russian Semantic Evaluation
Russian Word Sense Induction Evaluation
The RUSSE competition will perform a systematic comparison and evaluation of the baseline and the most recent approaches to word sense induction and disambiguation.
На arxiv.org опубликована наша статья, посвященная оценке моделей ELMo на задаче word sense disambiguation. В конце сентября мы представим эту статью на воркшопе конференции NODALIDA 2019, посвященном глубокому обучению в задачах обработки естественного языка.