
Please open Telegram to view this post
VIEW IN TELEGRAM
Что будет, если скомпилировать и запустить этот код?
Anonymous Quiz
23%
Ошибка во время компиляции
6%
NullPointerException
20%
StackOverflowError
35%
Код отработает успешно
17%
Узнать ответ
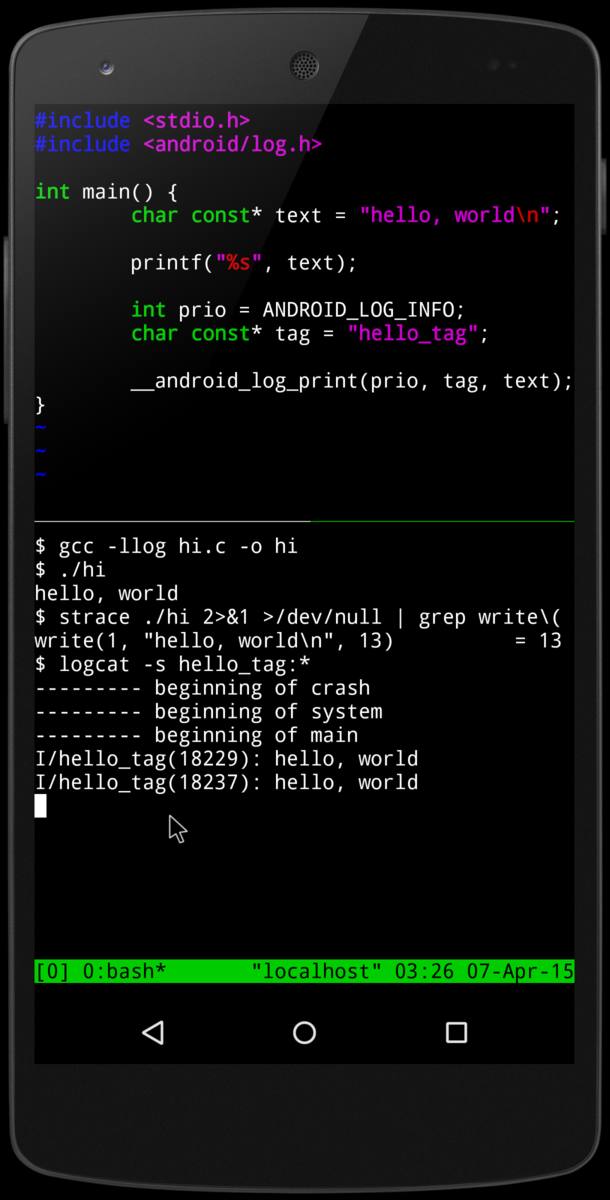
Termux - это эмулятор терминала Android и приложение среды Linux, написанный на Java.
Он работает напрямую без рутирования или настройки. Минимальная базовая система устанавливается автоматически - дополнительные пакеты доступны с помощью менеджера пакетов APT.
Termux-app - Пользовательский интерфейс и эмуляция терминала
Termux-api - Android API для использования командной строки и скриптов или программ
Termux-styling (Kotlin) - Дополнительное приложение для настройки шрифтов, терминала и цветовой схемы
Termux-tasker - Дополнительное приложение для интеграции с Tasker
Termux-packages (Shell) - Сборка системы и первичный набор пакетов для Termux
@javatg
Он работает напрямую без рутирования или настройки. Минимальная базовая система устанавливается автоматически - дополнительные пакеты доступны с помощью менеджера пакетов APT.
Termux-app - Пользовательский интерфейс и эмуляция терминала
Termux-api - Android API для использования командной строки и скриптов или программ
Termux-styling (Kotlin) - Дополнительное приложение для настройки шрифтов, терминала и цветовой схемы
Termux-tasker - Дополнительное приложение для интеграции с Tasker
Termux-packages (Shell) - Сборка системы и первичный набор пакетов для Termux
@javatg
{kind=link}
Допустим, мы вставлем 8 значений в hashmap, у ключей одинаковый hashcode, но разный equals.
Все значения попадут в одну ячейку, будут выстроены в дерево.
Вопрос, как в java происходит выбор места куда новый элемент вставить в дерево, в случае коллизии? При этом ключи не comparable
В таком случае в HashMap существует утилитный метод tieBreakOrder, который формирует порядок взаимоотношения между объектами исходя из их identity hash code:
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
В официальной документации классу Reader дано следующее определение: "BufferedReader считывает текст из символьного потока ввода, буферизируя прочитанные символы. Использование буфера призвано увеличить производительность чтения данных из потока".
Вопрос: каким образом использование буфера увеличивает производительность, по сравнению с использованием обычных ридеров?
"Обычные" (т.е. не обёрнутые в BufferedReader) ридеры за каждым чтением символов обращаются к источнику (например, файлу), что является относительно затратным по времени делом. Например, у вас есть файл, содержащий в себе довольно много символов, и вы хотите посимвольно прочитать его при помощи обычного FileReader. В таком случае каждый ваш вызов метода read(), читающий один отдельный символ, будет порождать обращение к файлу, и вы обратитесь к нему столько раз, сколько в нём имеется символов.
А BufferedReader же работает таким образом, что он обращается к источнику, считывает оттуда сразу много символов (по умолчанию 8192), занося их в определённый массив, и при следующих вызовах методов read() или readLine() символы будут читаться из этого массива, что конечно же намного быстрее.
Так что если вы захотите посимвольно прочитать текстовый файл, но уже с использованием BufferedReader, то при первом вызове метода read() сразу 8192 символа будет буферизовано, и при следующих вызовах метода символы просто будут браться из буфера.
Замерим время чтения текстового документа, состоящего примерно из ста тысяч символов, без использования BufferedReader и с ним.
Без использования BufferedReader:
long start = System.currentTimeMillis();
try(FileReader fileReader = new FileReader("sometxt.txt")) {
int i;
do {
i = fileReader.read();
} while (i != -1);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("Time: " + (System.currentTimeMillis() - start));
Результат:
Time: 428
А теперь с использованием BufferedReader:
long start = System.currentTimeMillis();
try(BufferedReader bufferedReader = new BufferedReader(new FileReader("sometxt.txt"))) {
int i;
do {
i = bufferedReader.read();
} while (i != -1);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("Time: " + (System.currentTimeMillis() - start));
Результат:
Time: 100@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
StackOverFlowError
Эта ошибка происходит, когда переполнен стек (по-английски - stack). Если кратко, то в стеке хранятся только ссылки на объекты, которые находятся в куче. Ещё в стеке хранятся примитивы и список методов, "кто кого вызвал". Вообщем StackOverFlowError происходит при зацикливании вызова методов. Например:
public static void doSomething(){
doSomething();
}
При вызове метода doSomething() произойдёт StackOverFlowError, так как стек будет переполнен.Чтобы исправить StackOverFlowError нужно найти такое зацикливание и убрать его. На самом деле, вызов метода из самого себя использовать можно, но делать это стоит осторожно. Это будет называться рекурсия. Вот пример использования рекурсии для вычисления факториала:
public static int factorial(int number){
if(number < 0){
throw new IllegalArgumentException("Число меньше 0");
}
if(number == 0 || number == 1){
return 1;
}
return factorial(number - 1) * number;
}
В таком случае StackOverFlowError не произойдёт, так как из метода в конце-концов будет выполнен выход.В рекурсивных методах следует также проверять, что число, пришедшее в параметрах, не слишком большое. В противном случае может оказаться, что метод будет вызывать сам себя хоть и не бесконечное, но всё же достаточное количество раз, чтобы произошла ошибка StackOverFlowError.
OutOfMemoryError
Это ошибка происходит, когда переполнена куча (по-английски - heap). Если кратко, то в куче хранятся объекты. Именно объекты, а не ссылки на них. То есть OutOfMemoryError произойдёт тогда, когда в куче кончится место создавать объекты. Вот пример:
public class Test{
public static void main(String [] args){
Object[][] toManyObjects = new Object[1000000][1000000];
}
}
Этот код бует скомпилирован, но при запуске произойдёт OutOfMemoryError:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at Test.main(Test.java:5)
Ведь в массиве гигантское количество объектов, и в куче нет столько места.Конечно, никто не будет делать такие глупые ошибки. Обычно OutOfMemoryError происходит тоже при зацикливании, но не при бесконечном вызове метода, а в обычных циклах (for, while, do-while), если из таких циклов нет выхода, а в теле цикла создаются какие-либо объекты.
Примеров кодов с OutOfMemoryError масса в интернете: можете посмотреть вопросы на StackOverFlow на русском, в которых упоминается OutOfMemoryError, если вам интересно посмотреть в каких случаях такая ошибка может произойти.
Подведу итоги
▪OutOfMemoryError происходит при переполнении кучи, а StackOverFlowError - при переполнении стека;
▪StackOverFlowError происходит при бесконечном вызове метода, а OutOfMemoryError - при зацикливании создания объектов;
▪И того, и другое нужно исправить: найти зацикливание и устранить его.
Ссылки
▪Статья на хабре про память в java
▪Ещё одна статья на хабре про память в java
▪Пост на английском StackOverFlow
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
Дан класс Film, у которого поле типа LocalDate должно быть не раньше 28 декабря 1895 года. Используем библиотеку javax.validation.constraints, где представлены
@Past, @Future, @FutureOrPresent, @PastOrPresent.
Для этой цели создадим свою кастомную аннотацию и валидатор. Пример статьи на эту тему
Класс аннотации
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = MinimumDateValidator.class)
@Past
public @interface MinimumDate {
String message() default "Date must not be before {value}";
Class<?>[] groups() default {};
Class<?>[] payload() default {};
String value() default "1895-12-28";
}
Кастомный класс валидатора, который будет эту аннотацию обрабатывать
public class MinimumDateValidator implements ConstraintValidator<MinimumDate, LocalDate> {
private LocalDate minimumDate;
@Override
public void initialize(MinimumDate constraintAnnotation) {
minimumDate = LocalDate.parse(constraintAnnotation.value());
}
@Override
public boolean isValid(LocalDate value, ConstraintValidatorContext context) {
return value == null || !value.isBefore(minimumDate);
}
}Для таких целей придется создать свою кастомную аннотацию и валидатор. Пример статьи на эту тему
Класс аннотации
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = MinimumDateValidator.class)
@Past
public @interface MinimumDate {
String message() default "Date must not be before {value}";
Class<?>[] groups() default {};
Class<?>[] payload() default {};
String value() default "1895-12-28";
}
Кастомный класс валидатора, который будет эту аннотацию обрабатывать
public class MinimumDateValidator implements ConstraintValidator<MinimumDate, LocalDate> {
private LocalDate minimumDate;
@Override
public void initialize(MinimumDate constraintAnnotation) {
minimumDate = LocalDate.parse(constraintAnnotation.value());
}
@Override
public boolean isValid(LocalDate value, ConstraintValidatorContext context) {
return value == null || !value.isBefore(minimumDate);
}
}Пример использования
public class Person {
@MinimumDate
private LocalDate birthDate;
}
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
Есть метод, который группирует элементы коллекции из нескольким полям.
public void test() {
List<Item> itemsList = ...//Чтение из XML;
Map<List<Object>, List<Item>> groupBy =
itemsList.stream().collect(Collectors.groupingBy(
i -> Arrays.asList(i.id, i.city, i.order_status)));
for (Map.Entry<List<Object>, List<Item>> t : groupBy.entrySet()) {
System.out.println(t.getKey());
for (Item item : t.getValue()) {
System.out.println(" " + item);
}
}
}Как сделать такое же без Stream API?
Для этого можно создать мапу с явным указанием типа ключа и значений, в цикле проходишь по списку и добавляешь элементы в мапу при помощи
Map::computeIfAbsent -- этот метод при необходимости создаёт новое или возвращает существующее значение-список, для которого можно сразу же вызвать метод List:add.При этом лучше использовать LinkedHashMap, чтобы порядок элементов в ней был стабильный (HashMap порядка не гарантирует).
public static Map<List<Object>, List<Item>> groupBy(List<Item> list) {
Map<List<Object>, List<Item>> map = new LinkedHashMap<>();
for (Item item : list) {
List<Object> key = Arrays.asList(item.getId(), item.getCity(), item.getOrderStatus());
map.computeIfAbsent(key, k -> new ArrayList<>()).add(item);
}
return map;
}
Это достаточно просто сделать при помощи кортежей record, официально поддерживаемых с Java 16, или Lombok-аннотаций
@Data / @AllArgsConstructor.enum OrderStatus {NEW, PROCESSING, COMPLETED, CANCELED};
// определены конструктор, геттеры без префикса `get`, hashCode / equals, toString
record MyKey(long id, String city, OrderStatus status) {
public MyKey(Item item) {
this(item.getId(), item.getCity(), item.getOrderStatus());
}
}
public static Map<MyKey, List<Item>> groupBy(List<Item> list) {
Map<MyKey, List<Item>> map = new LinkedHashMap<>();
list.forEach(item -> map
.computeIfAbsent(new MyKey(item), k -> new ArrayList<>())
.add(item)
);
// отладочный вывод
map.forEach((key, val) -> {
System.out.println(key);
val.forEach(item -> System.out.println("\t" + item));
});
return map;
}
При желании создание такой группировки можно параметризовать для любого ключа, если передавать некую функцию-конвертор Function<Item, Key>, в последнем примере такой функцией был конструктор кортежа MyKey(Item item). Например, для генерации ключа-списка можно было бы определить отдельный фабричный метод:
// MyClass
public static List<Object> keyIdCityStatus(Item item) {
return Arrays.asList(item.getId(), item.getCity(), item.getOrderStatus());
}
Параметризованный метод выглядит так:
public static<K> Map<K, List<Item>> groupBy(Function<Item, K> keyBuilder, List<Item> list) {
Map<K, List<Item>> map = new LinkedHashMap<>();
list.forEach(item -> map
.computeIfAbsent(keyBuilder.apply(item), k -> new ArrayList<>())
.add(item)
);
return map;
}
Соответственно вызывать его можно для любого ключа:
// ссылка на фабричный метод MyClass::keyIdCityStatus
Map<List<Object>, List<Item>> keyListMap = groupBy(MyClass::keyIdCityStatus, list);
// ссылка на конструктор MyKey::new
Map<MyKey, List<Item>> keyRecordMap = groupBy(MyKey::new, list);@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
Бесплатный курс по Kotlin и Android
Курс длится 10 часов. Конечно, выучить всё за такое короткое время невозможно, но вот познакомиться с основами — можно. На курсе вы изучите:
— основы Kotlin,
— жизненный цикл Android-приложений,
— эффективное использование Android Studio и Android SDK,
—Material design, анимации и многое другое.
Скачать курс можно по ссылке:
https://www.coursesbag.com/android-app-development-in-10-hours-bootcamp-android-13/
#android
@javatg
Курс длится 10 часов. Конечно, выучить всё за такое короткое время невозможно, но вот познакомиться с основами — можно. На курсе вы изучите:
— основы Kotlin,
— жизненный цикл Android-приложений,
— эффективное использование Android Studio и Android SDK,
—Material design, анимации и многое другое.
Скачать курс можно по ссылке:
https://www.coursesbag.com/android-app-development-in-10-hours-bootcamp-android-13/
#android
@javatg
Даны три строки кода:
String s = null;
s = "Hellow";
s = null;Создали переменную s типа String, которая ни на что не ссылается (хранит пустую ссылку null).
Создаем объект-строку Hellow, переменная s хранит ссылку на объект.
Удаляем из переменной s ссылку на объект.
Вопрос: что происходит со строкой Hellow после удаления ссылки на неё? Остаётся ли она в памяти или удаляется вместе со ссылкой?
В данном сценарии строковый литерал "Hellow" определён в момент компиляции и соответственно будет размещён в пуле строк (string pool).
В старых версиях (Java 6 и раньше) пул строк являлся частью постоянной области памяти PermGen, которая не относилась к основной куче (Heap) и имела постоянный размер, который нельзя было увеличить.
Сборка мусора запускается только при условии, что существующая память исчерпана. Как правило, вероятность такого сценария для постоянной области памяти пренебрежимо мала -- нужно было бы или загружать множество классов или постоянно добавлять в пул новые строки при помощи String::intern. В худшем случае можно было бы добиться и OutOfMemoryError.
Начиная с Java 7 и выше пул строк размещается в куче (heap), для которой сборка мусора вызывается чаще (по сравнению с PermGen), при этом неиспользуемые строки удаляются из пула, освобождая память.
При необходимости размер кучи может увеличиваться, в том числе и превышая объём доступной физической памяти.
#junior #java
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Java Jobs
Java программист Senior/Lead
Формат: классный офис в Москве/гибрид/удаленно;
Доход: 300-400К руб.;
Форма оформления: по ТК/ИП.
О нас: Мы занимаемся разработкой data-платформы, в рамках которой развиваются различные data-продукты:
• рекомендательные системы;
• сервисы аналитики и визуализации данных;
• ML-модели;
• иные решения для решения бизнес-задач.
Наша команда это 25 инженеров с сильнейшими компетенциями в ML, аналитике и работе с данными, и сейчас мы ищем классных ребят для дальнейшего роста.
У нас нет долгих согласований и бюрократии. Мы стремимся к быстрому внедрению в production, с последующей работой над улучшениями.
Что нужно будет делать:
• Разработка высоконагруженных приложений в рамках Платформы данных;
• Участие в проектировании сервисов и компонентов Платофрмы данных;
• Обеспечение высокого качества кода и улучшение внутренних процессов инженерии ПО;
• Участие в оценке и декомпозиции задач вместе с Front-End, DevOps, Data и ML инженерами.
Будет классно, если у тебя:
• Опыт построения высоконагруженных бэкенд сервисов (на Java, от 3х лет) в крупных продуктовых компаниях;
• Опыт работы с реляционными базами данных (желательно, PostgreSQL);
• Понимание архитектурных стилей API для клиент-серверного и межсерверного взаимодействия (GraphQL, REST, gRPC)
• Хорошее знание Spring / Spring Boot (Core, Data, JPA и т.д.);
• Понимание базовых алгоритмов и структур данных;
• Знание гибких методологий разработки программного обеспечения.
Ты покоришь наши сердца и разум, если у тебя:
• Опыт контейнеризации Java-приложений (Docker, Kubernetes);
• Опыт работы с публичными облаками, особенно, с Яндекс.Облаком;
• Опыт работы с NoSQL базами данных;
• Понимание особенностей работы с аналитическими базами данных, например, с ClickHouse;
• Опыт интеграции моделей машинного обучения в Java-сервисы;
• Опыт работы с распределенными очередями и брокерами, например, Kafka или RabbitMQ.
Мы предлагаем:
• Работу в аккредитованной IT компании с сильнейшей командой в разных масштабных проектах;
• Гибридный график работы 5/2, с 10:00 - 19:00;
• ДМС со стоматологией;
• В современном офисе в стиле Лофт с капсулой медитации, спортзалом, большой современной библиотекой и кабинетом для записи подкастов и треков;
• Комфортную кухню с холодильником, кофемашиной, тостером, микроволновкой и Magic Bullet;
• Холодильник с напитками (соки, энергетики, вода и т.д.) и едой (сыры, колбасы, сырки и м.ч.);
• Каждую пятницу совместные обеды с разными кухнями мира за счет компании.
За подробностями пиши: tg @naikava
@Java_workit - вакансии для java разработчиков
Формат: классный офис в Москве/гибрид/удаленно;
Доход: 300-400К руб.;
Форма оформления: по ТК/ИП.
О нас: Мы занимаемся разработкой data-платформы, в рамках которой развиваются различные data-продукты:
• рекомендательные системы;
• сервисы аналитики и визуализации данных;
• ML-модели;
• иные решения для решения бизнес-задач.
Наша команда это 25 инженеров с сильнейшими компетенциями в ML, аналитике и работе с данными, и сейчас мы ищем классных ребят для дальнейшего роста.
У нас нет долгих согласований и бюрократии. Мы стремимся к быстрому внедрению в production, с последующей работой над улучшениями.
Что нужно будет делать:
• Разработка высоконагруженных приложений в рамках Платформы данных;
• Участие в проектировании сервисов и компонентов Платофрмы данных;
• Обеспечение высокого качества кода и улучшение внутренних процессов инженерии ПО;
• Участие в оценке и декомпозиции задач вместе с Front-End, DevOps, Data и ML инженерами.
Будет классно, если у тебя:
• Опыт построения высоконагруженных бэкенд сервисов (на Java, от 3х лет) в крупных продуктовых компаниях;
• Опыт работы с реляционными базами данных (желательно, PostgreSQL);
• Понимание архитектурных стилей API для клиент-серверного и межсерверного взаимодействия (GraphQL, REST, gRPC)
• Хорошее знание Spring / Spring Boot (Core, Data, JPA и т.д.);
• Понимание базовых алгоритмов и структур данных;
• Знание гибких методологий разработки программного обеспечения.
Ты покоришь наши сердца и разум, если у тебя:
• Опыт контейнеризации Java-приложений (Docker, Kubernetes);
• Опыт работы с публичными облаками, особенно, с Яндекс.Облаком;
• Опыт работы с NoSQL базами данных;
• Понимание особенностей работы с аналитическими базами данных, например, с ClickHouse;
• Опыт интеграции моделей машинного обучения в Java-сервисы;
• Опыт работы с распределенными очередями и брокерами, например, Kafka или RabbitMQ.
Мы предлагаем:
• Работу в аккредитованной IT компании с сильнейшей командой в разных масштабных проектах;
• Гибридный график работы 5/2, с 10:00 - 19:00;
• ДМС со стоматологией;
• В современном офисе в стиле Лофт с капсулой медитации, спортзалом, большой современной библиотекой и кабинетом для записи подкастов и треков;
• Комфортную кухню с холодильником, кофемашиной, тостером, микроволновкой и Magic Bullet;
• Холодильник с напитками (соки, энергетики, вода и т.д.) и едой (сыры, колбасы, сырки и м.ч.);
• Каждую пятницу совместные обеды с разными кухнями мира за счет компании.
За подробностями пиши: tg @naikava
@Java_workit - вакансии для java разработчиков
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,
"Joseph Smith", "Thomas Doyle", "Ronald Pratt", "Thomas Spencer", "King Lee",
"Gregory Smith", "Leroy Zimmerman", "Lee Smith", "Michael Harrington",
"Lee Daniels","Eugene Williams", "Lee Terry", "Arnold Fowler", "Billy Harrison",
"Lee Bennett", "Lee Evans", "Ronald Diaz", "Leonard King", "Timothy Smith",
"George Lee", "King Mann", "Dean Wright"
);
list.stream()
.filter(s -> s.contains("K") || s.contains("S"))
.filter(s -> !s.startsWith("K")&&!s.startsWith("S"))
.sorted().distinct()
.collect(Collectors.toList());Метод должен вернуть имена людей, чья фамилия начинается с K или S, в формате имя + первая буква фамилии, например "David Z.". Список должен быть отсортирован по алфавиту и состоять только из уникальных значений
Ответ
Для данных, представленных в формате "{firstName} {lastName}" можно отфильтровать слова при помощи String::matches и регулярного выражения типа
"\\w+ [KS]\\w+". Соответственно, к отфильтрованным слов достаточно будет применить String::substring:
List<String> list = Arrays.asList(
"Joseph Smith", "Thomas Doyle", "Ronald Pratt", "Thomas Spencer", "King Lee",
"Gregory Smith", "Leroy Zimmerman", "Lee Smith", "Michael Harrington", "Lee Daniels","Eugene Williams",
"Lee Terry", "Arnold Fowler", "Billy Harrison", "Lee Bennett", "Lee Evans", "Ronald Diaz",
"Leonard King", "Timothy Smith", "George Lee", "King Mann", "Dean Wright"
);
List<String> fixed = list.stream()
.filter(s -> s.matches("\\w+ [KS]\\w+"))
.map(s -> s.substring(0, s.indexOf(" ") + 2) + ".")
.sorted()
.distinct()
.collect(Collectors.toList());
System.out.println(fixed);
// -> [Gregory S., Joseph S., Lee S., Leonard K., Thomas S., Timothy S.]Если имена состоят из трех и больше частей, но фамилией является последняя часть, регулярное выражение
".+ [KS]\\w+" и поиск фамилии следует исправить (искать последний пробел при помощи String::lastIndexOf):List<String> list = Arrays.asList(
"Joseph Smith", "Thomas Doyle", "Ronald Pratt Kimberly", "Thomas Spencer", "King Lee Roy Stapleton",
"Gregory Smith", "Leroy Zimmerman", "Lee Smith Jacob", "Michael Harrington", "Lee Daniels","Eugene Williams",
"Lee Terry", "Arnold Fowler", "Billy Harrison", "Lee Bennett", "Lee Evans", "Ronald Diaz",
"Leonard King", "Timothy Smith", "George Lee", "King Mann", "Dean Wright"
);
List<String> fixed = list.stream()
.filter(s -> s.matches(".+ [KS]\\w+"))
.map(s -> s.substring(0, s.lastIndexOf(" ") + 2) + ".")
.sorted()
.distinct()
.collect(Collectors.toList());
System.out.println(fixed);
// -> [Gregory S., Joseph S., King Lee Roy S., Leonard K., Ronald Pratt K., Thomas S., Timothy S.]
String::replaceAll для замены части фамилии на точку -- выглядит более "красиво":
List<String> fixed = list.stream()
.filter(s -> s.matches("(.+ [KS])(.*$)"))
.map(s -> s.replaceAll("(.+ [KS])(.*$)", "$1."))
.sorted()
.distinct()
.collect(Collectors.toList()); 👉 Пишите ваше решение в комментариях👇
javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
Книга рецептов на Java
Руководство по созданию простой системы управления рецептами на Java. В приложении Recipe Manager хранятся непосредственно данные о рецепте, которые пользователь можно легко изменить. UI очень простой, но для реализации проекта также понадобится подключить базу данных:
https://myprojectideas.com/recipe-management-system-in-java-java-project/
#java
@javatg
Руководство по созданию простой системы управления рецептами на Java. В приложении Recipe Manager хранятся непосредственно данные о рецепте, которые пользователь можно легко изменить. UI очень простой, но для реализации проекта также понадобится подключить базу данных:
https://myprojectideas.com/recipe-management-system-in-java-java-project/
#java
@javatg
🔥 Top it channels
🖥 SQL базы данных
@sqllib - библиотека баз данных
@sqlhub - повышение эффективности кода с грамотным использованием бд.
@chat_sql - чат изучения бд.
⭐️ Нейронные сети
@data_analysis_ml - data science
@vistehno - chatgpt ведет блог, решает любые задачи и отвечает на любые ваши вопросы.
@aigen - сети для генерации картинок. видео, музыки и многого другого.
@neural – погружение в нейросети.
🖥 Machine learning
@ai_ml – погружение в нейросети, ai, Chatgpt, midjourney, машинное обучение.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседованию.
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
@Machinelearning_Jobs - чат работы мл
🖥 Python
@pythonl - главный канал самого популярного языка программирования.
@pro_python_code – учим python с ментором.
@python_job_interview – подготовка к Python собеседованию.
@python_testit - проверочные тесты на python
@pythonlbooks - современные книги Python
@python_djangojobs - работа для Python программистов
@python_django_work - чат обсуждения вакансий
🖥 Javascript / front
@react_tg - - 40,14% разработчиков сайтов использовали React в 2022 году - это самая популярная библиотека для создания сайтов.
@javascript -канал для JS и FrontEnd разработчиков. Лучшие практики и примеры кода. Туториалы и фишки JS
@Js Tests - каверзные тесты JS
@hashdev - погружение в web разработку.
@javascriptjobjs - отборные вакансии и работа FrontEnd.
@jsspeak - чат поиска FrontEnd работы.
🖥 Java
@javatg - выучить Java с senior разработчиком по профессиональной методике.
@javachats - чат для ответов на вопросы по Java
@java_library - библиотека книг Java
@android_its - Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
👣 Golang
@Golang_google - восхитительный язык от Google, мощный и перспективный.
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@golangtests - интересные тесты и задачи GO
@golangl - чат изучающих Go
@GolangJobsit - отборные вакансии и работа GO
@golang_jobsgo - чат для ищущих работу.
@golang_books - полезные книги Golang
@golang_speak - обсуждение языка Go
🖥 Linux
@linux -топ фишки, гайды, уроки по работе с Linux.
@linux chat - чат linux для обучения и помощи.
@linux_read - бесплатные книги linux
👷♂️ IT работа
@hr_itwork -кураторский список актуальных ит-ваканнсии
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - Rust избавлен от болевых точек, которые есть во многих современных яп
@rust_chats - чат rust
#️⃣ c# c++
C# - объединяет лучшие идеи современных языков программирования
@csharp_cplus чат
С++ - Универсальность. Возможно, этот главный плюс C++.
📓 Книги
@programming_books_it - большая библиотека. программиста
@datascienceiot -ds книги
@pythonlbooks - python библиотека.
@golang_books - книги Golang
@frontendbooksit - front книги
@progersit - ит-шпаргалки
@linux_read - Linux books
@java_library - Java books
🖥 Github
@github_code - лучшие проекты с github
@bigdatai - инструменты по работе с данными
🖥 Devops
Devops - специалист общего профиля, которому нужны обширные знания в области разработки.
📢 English for coders
@english_forprogrammers - Английский для программистов
💡 ChatGpt bot
@Chatgpturbobot - бесплатный бот ChatGpt
@sqllib - библиотека баз данных
@sqlhub - повышение эффективности кода с грамотным использованием бд.
@chat_sql - чат изучения бд.
@data_analysis_ml - data science
@vistehno - chatgpt ведет блог, решает любые задачи и отвечает на любые ваши вопросы.
@aigen - сети для генерации картинок. видео, музыки и многого другого.
@neural – погружение в нейросети.
@ai_ml – погружение в нейросети, ai, Chatgpt, midjourney, машинное обучение.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседованию.
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
@Machinelearning_Jobs - чат работы мл
@pythonl - главный канал самого популярного языка программирования.
@pro_python_code – учим python с ментором.
@python_job_interview – подготовка к Python собеседованию.
@python_testit - проверочные тесты на python
@pythonlbooks - современные книги Python
@python_djangojobs - работа для Python программистов
@python_django_work - чат обсуждения вакансий
@react_tg - - 40,14% разработчиков сайтов использовали React в 2022 году - это самая популярная библиотека для создания сайтов.
@javascript -канал для JS и FrontEnd разработчиков. Лучшие практики и примеры кода. Туториалы и фишки JS
@Js Tests - каверзные тесты JS
@hashdev - погружение в web разработку.
@javascriptjobjs - отборные вакансии и работа FrontEnd.
@jsspeak - чат поиска FrontEnd работы.
@javatg - выучить Java с senior разработчиком по профессиональной методике.
@javachats - чат для ответов на вопросы по Java
@java_library - библиотека книг Java
@android_its - Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
@Golang_google - восхитительный язык от Google, мощный и перспективный.
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@golangtests - интересные тесты и задачи GO
@golangl - чат изучающих Go
@GolangJobsit - отборные вакансии и работа GO
@golang_jobsgo - чат для ищущих работу.
@golang_books - полезные книги Golang
@golang_speak - обсуждение языка Go
@linux -топ фишки, гайды, уроки по работе с Linux.
@linux chat - чат linux для обучения и помощи.
@linux_read - бесплатные книги linux
👷♂️ IT работа
@hr_itwork -кураторский список актуальных ит-ваканнсии
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - Rust избавлен от болевых точек, которые есть во многих современных яп
@rust_chats - чат rust
#️⃣ c# c++
C# - объединяет лучшие идеи современных языков программирования
@csharp_cplus чат
С++ - Универсальность. Возможно, этот главный плюс C++.
📓 Книги
@programming_books_it - большая библиотека. программиста
@datascienceiot -ds книги
@pythonlbooks - python библиотека.
@golang_books - книги Golang
@frontendbooksit - front книги
@progersit - ит-шпаргалки
@linux_read - Linux books
@java_library - Java books
@github_code - лучшие проекты с github
@bigdatai - инструменты по работе с данными
Devops - специалист общего профиля, которому нужны обширные знания в области разработки.
@english_forprogrammers - Английский для программистов
@Chatgpturbobot - бесплатный бот ChatGpt
Please open Telegram to view this post
VIEW IN TELEGRAM
Задачи на алгоритмы и их решения
The Algorithms — проект с открытым исходным кодом, созданный группой разработчиков для понимания структур данных и алгоритмов на разных языках. Любой желающий может внести свой вклад в проект или помочь решить задачу других:
1. Java
2. JavaScript
3. Python
4. Go
#алгоритмы
The Algorithms — проект с открытым исходным кодом, созданный группой разработчиков для понимания структур данных и алгоритмов на разных языках. Любой желающий может внести свой вклад в проект или помочь решить задачу других:
1. Java
2. JavaScript
3. Python
4. Go
#алгоритмы
Snyk — платформа для поиска уязвимостей
Инструмент умеет работать со множеством экосистем: JavaScript, Ruby, Python, Scala и Java. При этом, по словам автором проекта, их база уязвимостей достигает каких-то гигантских размеров
При этом посмотреть на неё можно и самим — код проекта открыт и лежит на GitHub
Стоимость: #бесплатно (но есть платные функции)
@javatg
Инструмент умеет работать со множеством экосистем: JavaScript, Ruby, Python, Scala и Java. При этом, по словам автором проекта, их база уязвимостей достигает каких-то гигантских размеров
При этом посмотреть на неё можно и самим — код проекта открыт и лежит на GitHub
Стоимость: #бесплатно (но есть платные функции)
@javatg
Java-фреймворк Helidon или просто ласточка
Helidon — легкий фреймворк для разработки микросервисов. В Helidon есть две основные модели программирования: Helidion SE и Helidon MP.
Helidion SE — набор реактивных API на Netty, который использует реактивные потоки, асинхронное и функциональное программирование, а также Fluent API. Благодаря этому, инициализация и запуск веб-приложений происходит быстрее.
Helidon MP — используется для поддержки SE в рамках стандартов MicroProfile: CDI, JSON-P, MicroProfile JWT Authentication, MicroProfile OpenAPI и т.д.
Документация: https://helidon.io/
#java
Helidon — легкий фреймворк для разработки микросервисов. В Helidon есть две основные модели программирования: Helidion SE и Helidon MP.
Helidion SE — набор реактивных API на Netty, который использует реактивные потоки, асинхронное и функциональное программирование, а также Fluent API. Благодаря этому, инициализация и запуск веб-приложений происходит быстрее.
Helidon MP — используется для поддержки SE в рамках стандартов MicroProfile: CDI, JSON-P, MicroProfile JWT Authentication, MicroProfile OpenAPI и т.д.
Документация: https://helidon.io/
#java
Знакомимся с Kotlin на практике
Хотите быстро приступить к написанию кода на Kotlin? Упражнения Kotlin Koans от JetBrains помогут освоить синтаксис языка и его идиомы. Задания выглядят как непройденные unit-тесты, и вам предстоит их успешно завершить.
Единственное условие — нужно знать какой-либо язык программирования, например Java.
Поупражняться: https://play.kotlinlang.org/koans/overview
#kotlin #курсы
@javatg
Хотите быстро приступить к написанию кода на Kotlin? Упражнения Kotlin Koans от JetBrains помогут освоить синтаксис языка и его идиомы. Задания выглядят как непройденные unit-тесты, и вам предстоит их успешно завершить.
Единственное условие — нужно знать какой-либо язык программирования, например Java.
Поупражняться: https://play.kotlinlang.org/koans/overview
#kotlin #курсы
@javatg