
Какой результат выведет следующая программа?
Anonymous Quiz
39%
Hello world!
32%
Ошибку при выполнении
30%
Ошибку компиляции
👍22👎8🔥2❤1
Наиболее простой/лаконичный современный (Java 8+) способ удаления элементов из коллекции -- использовать метод
Collection::removeIf, в который следует передать функцию-предикат для определения удаляемых элементов. Также для проверки на чётность можно проверять младший бит на равенство 0:List<Integer> data = new ArrayList<>(Arrays.asList(2,3,4,6,8,10,22,-2,-5,0));
data.removeIf(n -> (n & 1) == 0); // [3, -5]Упомянутый метод использует под капотом итератор и его метод
Iterator::remove, который как раз рекомендуется для безопасного удаления элементов из коллекции при прохождении по ней, так как позволяет избежать излишних сложностей с индексной арифметикой и проблем с ConcurrentModificationException со времён Java 1.2 и появления Collection Framework.
List<Integer> data = new ArrayList<>(Arrays.asList(2,3,4,6,8,10,22,-2,-5,0));
for (Iterator<Integer> it = data.iterator(); it.hasNext();) {
if (0 == (it.next() & 1)) {
it.remove();
}
}Однако если стоит задача реализовать удаление именно с использованием индексов, можно удалять элементы с конца, согласно совета в комментариях:
for (int i = data.size(); i-- > 0;) {
if (data.get(i) % 2 == 0) {
data.remove(i);
}
}
for (int i = 0, n = data.size(); i < n; i++) {
if (data.get(i) % 2 == 0) {
data.remove(i--); // коррекция индекса при удалении
n--; // коррекция размера списка
}
}
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍10❤2🔥1😢1
Возможно, вы уже встречались с таким понятием, как структурированная конкурентность, и пытались прояснить для себя его суть. Структурированная конкурентность — это парадигма, которая стремится упростить чтение и понимание конкурентных программ, ускорить их написание и обеспечить их безопасность.
Прежде чем приступить к детальному разбору данной темы, обоснуем ее актуальность.
▪Читать
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍6🔥4❤2
Решение:
class StepThread extends Thread {
// общий для двух потоков lock
private Object lock;
public StepThread(Object object) {
this.lock = object;
}
/**
* Идея такая: выводим имя потока, потом поток засыпает,
* перед этим уведомив другой поток, о том, что теперь его очередь.
*
* После вызова первым потоком lock.notify() второй поток
* не просыпается сразу, а ждёт,
* пока lock не будет освобождён. А когда это происходит, уже вызван
* метод lock.wait(), и первый поток ждёт своей очереди. И так по кругу.
*/
@Override
public void run() {
while (true) {
synchronized (lock) {
try {
System.out.println(getName());
lock.notify();
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
public class Main {
public static void main(String[] strings) {
Object lock = new Object();
new StepThread(lock).start();
new StepThread(lock).start();
}
}Пишите свое решение в комментариях👇
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍10🔥3❤1
Бибилиотека предоставляет набор инструментов для анализа естественного языка (NLP), написанных на Java.
CoreNLP может принимать необработанный текст на 8 языках и определять базовые формы слов, их части речи, названия компаний, людей и т.д., нормализовать и интерпретировать даты, время и числовые величины, обозначать структуру предложений в терминах фраз или зависимостей слов, а также указывать, какие фразы существительных относятся к одним и тем же сущностям
📌Документация
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍10❤2🔥1
Для этого делегируйте все методы стандартному StringBuilder, а в собственном классе храните список всех операций для выполнения undo(). Это будет реализацией шаблона «Команда».
Решение
/**
* StringBuilder с поддержкой операции undo
* java.lang.StringBuilder — класс с модификатором <b>final</b>,
* поэтому нет наследования, используем делегирование.
*/
class UndoableStringBuilder {
private interface Action{
void undo();
}
private class DeleteAction implements Action{
private int size;
public DeleteAction(int size) {
this.size = size;
}
public void undo(){
stringBuilder.delete(
stringBuilder.length() - size, stringBuilder.length());
}
}
private StringBuilder stringBuilder; // делегат
/**
* операции, обратные к выполненным.
* То есть при вызове append, в стек помещается
* операция "delete". При вызове undo() она
* будет выполнена.
*/
private Stack<Action> actions = new Stack<>();
// конструктор
public UndoableStringBuilder() {
stringBuilder = new StringBuilder();
}
/**
see {@link java.lang.AbstractStringBuilder#reverse()}
После того, как сделан reverse(),
добавляем в стек операций обратную — тоже reverse().
Далее таким же образом.
*/
public UndoableStringBuilder reverse() {
stringBuilder.reverse();
Action action = new Action(){
public void undo() {
stringBuilder.reverse();
}
};
actions.add(action);
return this;
}
public UndoableStringBuilder append(String str) {
stringBuilder.append(str);
Action action = new Action(){
public void undo() {
stringBuilder.delete(
stringBuilder.length() - str.length() -1,
stringBuilder.length());
}
};
actions.add(action);
return this;
}
// ..... остальные перегруженые методы append пишутся аналогично (см. выше)......
public UndoableStringBuilder appendCodePoint(int codePoint) {
int lenghtBefore = stringBuilder.length();
stringBuilder.appendCodePoint(codePoint);
actions.add(new DeleteAction(stringBuilder.length() - lenghtBefore));
return this;
}
public UndoableStringBuilder delete(int start, int end) {
String deleted = stringBuilder.substring(start, end);
stringBuilder.delete(start, end);
actions.add(() -> stringBuilder.insert(start, deleted));
return this;
}
public UndoableStringBuilder deleteCharAt(int index) {
char deleted = stringBuilder.charAt(index);
stringBuilder.deleteCharAt(index);
actions.add(() -> stringBuilder.insert(index, deleted));
return this;
}
public UndoableStringBuilder replace(int start, int end, String str) {
String deleted = stringBuilder.substring(start, end);
stringBuilder.replace(start, end, str);
actions.add(() -> stringBuilder.replace(start, end, deleted));
return this;
}
public UndoableStringBuilder insert(int index, char[] str, int offset, int len) {
stringBuilder.insert(index, str, offset, len);
actions.add(() -> stringBuilder.delete(index, len));
return this;
}
public UndoableStringBuilder insert(int offset, String str) {
stringBuilder.insert(offset, str);
actions.add(() -> stringBuilder.delete(offset, str.length()));
return this;
}
// ..... остальные перегруженные методы insert пишутся аналогично (см. выше)......
public void undo(){
if(!actions.isEmpty()){
actions.pop().undo();
}
}
public String toString() {
return stringBuilder.toString();
}
}
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍11🔥3❤2👏2
В этом посте я приведу пример, как можно использовать нейросеть ChatGpt для помощи в работе при написании Java кода.
Я привел свои запросы и ответы с кодом от ChatGPt, оцените качество кода, который пишет бот.
▪Читать
▪Как писать код с ChatGpt
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍15🔥2🥰1
T extends Comparable<T>
Описывает переменную типа, ограниченную сверху при помощи
extends, то есть, некий обобщённый класс T должен реализовать интерфейс Comparable<T>, т.е. объекты такого класса поддерживают естественный порядок и их можно сравнивать и упорядочивать при помощи метода int compareTo(T that).Может использоваться для обычных обобщённых классов
public class Foo<T extends Comparable<T>> {
private T field;
//геттер/сеттер/конструктор
}
т.е. класс Foo может создаваться не для любых классов T, а только реализующих Comparable типа Integer, String, LocalDate, и т.п.:Foo<Integer> fooInt = new Foo<>(123); // ok
Foo<Random> fooRand = new Foo<>(new Random()); // ошибка, Random не является Comparable
// Type parameter 'java.util.Random' is not within its bound; should implement 'java.lang.Comparable<java.util.Random>'
Соответственно, массивы/списки/стримы таких объектов можно сортировать, для них можно искать минимум/максимум и т.д.:
Collections :: public static <T extends Comparable<? super T>> void sort(List<T> list)
Доп.информация:
Oracle Tutorial: Bounded Type Parameters
? extends Comparable
Такая запись называется wildcard или подстановкой с верхней границей (upper-bounded).
С её помощью можно организовать ковариантность, т.е. List<Integer> является подтипом List<Comparable>. List<? extends Comparable> может содержать объекты, которые являются Comparable или наследуются от Comparable.
Это можно применять для того, чтобы коллекции классов, реализующих Comparable, присвоить коллекцию объектов с конкретными реализациями:
List<Integer> ints = Arrays.asList(4, 2, 3);
List<String> strs = Arrays.asList("111", "xxxx", "aaaa");
List<LocalDate> dats = Arrays.asList(LocalDate.now(), LocalDate.of(2020, 11, 1), LocalDate.of(2025, 5, 12));
List<? extends Comparable> comps = ints;
comps = strs;
comps = dats;или же передать такую коллекцию в некий метод, например, для сортировки:
public static void sortAndPrint(List<? extends Comparable> list) {
Collections.sort(list);
System.out.println("sorted: " + list);
}
sortAndPrint(ints); // sorted: [2, 3, 4]
sortAndPrint(strs); // sorted: [111, aaaa, xxxx]
sortAndPrint(dats); // sorted: [2020-11-01, 2023-02-20, 2025-05-12]
Такая запись называется подстановкой с нижней границей (lower-bounded).
С её помощью можно организовать контравариантность, т.е. List<Comparable> является подтипом List<? super Integer>.
Также можно использовать для присваивания или передачи в функции:
List<Comparable> comps2 = Arrays.asList(269, 123, 351);
List<? super Integer> ints2 = comps2;
// Collections.sort(ints2); // Ошибка!
// reason: no instance(s) of type variable(s) T exist so that capture of ? super Integer conforms to Comparable<? super T>
Collections.sort(comps2);
System.out.println(ints2); // [123, 269, 351]
Коллекция с типом ? super T может использоваться только в качестве приёмника данных, например, для копирования списков существует метод:
Collections::public static <T> void copy(List<? super T> dest, List<? extends T> src) :
Collections.copy(ints2, ints);
System.out.println(comps2); // [2, 3, 4]
System.out.println(ints2); // [2, 3, 4]@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍21🔥3🤔2❤1
Приватные статические методы можно объявлять не только в интерфейсах, но и в обычных классах. Эти методы можно вызывать из публичных статических методов, собственно, в этом и состоит их назначение. Например, несколько public static методов имеют общую часть работы. Тогда её можно вынести в отдельный метод, который они будут вызывать, но при этом такой метод может не иметь ценности для человека, использующего наш класс (ведь он может выполнять чисто промежуточную работу), поэтому мы объявляем его как private.
В качестве примера можно рассмотреть любой
utility-класс, например, Collections. Там имеется очень много private static методов.Точно также дело обстоит и с
private static методами в интерфейсах. В интерфейсе может быть множество разных public static методов, опирающихся в своей работе на какой-нибудь выполняющий промежуточную работу private static метод. Ниже приведу пример, как это может быть, хоть пример и немного высосан из пальца.public interface SomeInterface {
static void printListIfSumMoreThan(List<Integer> list, int sum) {
if (sum(list) > sum) {
list.forEach(System.out::println);
}
// этот метод выводит элементы списка, если их сумма больше, чем sum
}
static void printListIfSumLessThan(List<Integer> list, int sum) {
if (sum(list) < sum) {
list.forEach(System.out::println);
}
// этот метод выводит элементы списка, если их сумма меньше, чем sum
}
private static int sum(List<Integer> list) {
return list.stream()
.mapToInt(elem -> elem)
.sum();
// а этот метод считает сумму: его работа - чисто промежуточная
}
}Зачем нам вообще может понадобиться
static метод в интерфейсе? За этим обратимся к интерфейсу Comparator. В нём есть много замечательных статических методов, один из которых - Comparator::comparing. Он предназначен для того, чтобы выдавать нам реализацию компаратора, которая сравнивает объекты по указанным полям. Совершенно очевидно, что этот метод не должен быть ни абстрактным, ни дефолтным. По задумке он именно статический, и вовсе не зря.А теперь вернёмся к моему примеру (код, приведённый выше) и представим, что оба статических метода
printListIfSumMoreThan и printListIfSumLessThan так же совершенно обоснованно являются статическими. При этом мы видим, что для того, чтобы они выполнили свою работу, им нужно найти сумму элементов в списке. Вычисление суммы - явно одинаковая подзадача для обоих методов, так зачем же писать код дважды? Вот мы и создаём отдельный метод, в который выносим код по вычислению суммы элементов в списке, а в тех двух методах просто используем его.Почему метод
sum является private? Потому что по задумке пользователь не должен его видеть, этот метод чисто "наш", служебный. Почему он static? Потому что статические методы могут оперировать только статическими методами. Если бы он не был статическим, то методы printListIfSumMoreThan и printListIfSumLessThan просто не смогли бы его вызвать, вот и всё.Так и получается, что иногда в интерфейсе могут понадобиться именно
private static методы.@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍22🔥3❤1
Что будет, если скомпилировать и запустить этот код?
Anonymous Quiz
23%
Ошибка во время компиляции
6%
NullPointerException
20%
StackOverflowError
35%
Код отработает успешно
17%
Узнать ответ
👍20😢14❤3🤩1
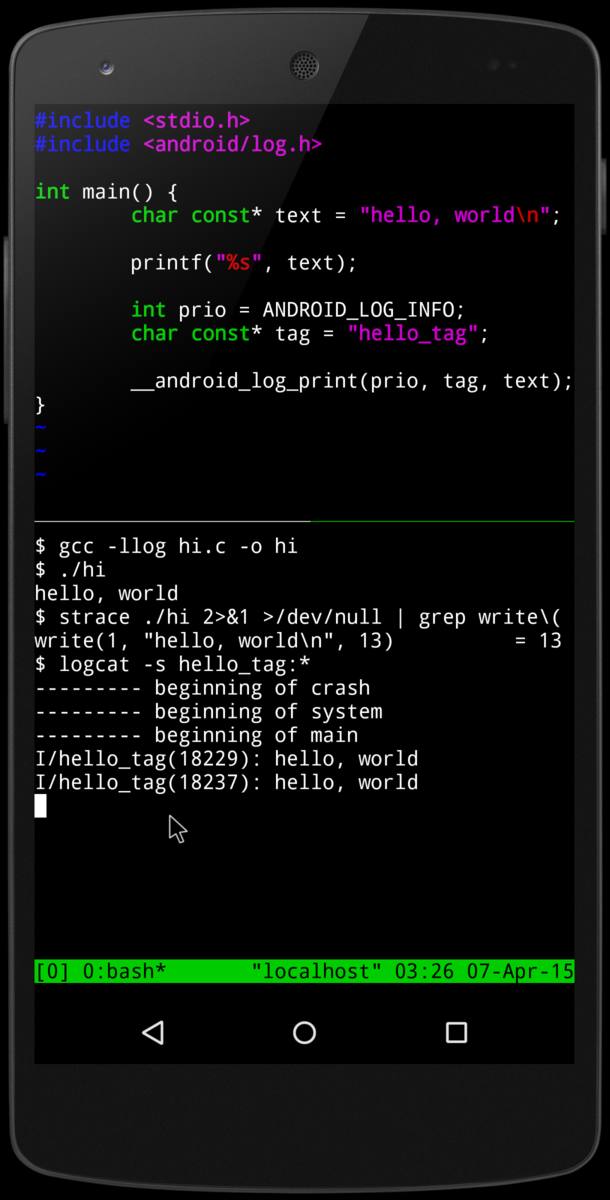
Termux - это эмулятор терминала Android и приложение среды Linux, написанный на Java.
Он работает напрямую без рутирования или настройки. Минимальная базовая система устанавливается автоматически - дополнительные пакеты доступны с помощью менеджера пакетов APT.
Termux-app - Пользовательский интерфейс и эмуляция терминала
Termux-api - Android API для использования командной строки и скриптов или программ
Termux-styling (Kotlin) - Дополнительное приложение для настройки шрифтов, терминала и цветовой схемы
Termux-tasker - Дополнительное приложение для интеграции с Tasker
Termux-packages (Shell) - Сборка системы и первичный набор пакетов для Termux
@javatg
Он работает напрямую без рутирования или настройки. Минимальная базовая система устанавливается автоматически - дополнительные пакеты доступны с помощью менеджера пакетов APT.
Termux-app - Пользовательский интерфейс и эмуляция терминала
Termux-api - Android API для использования командной строки и скриптов или программ
Termux-styling (Kotlin) - Дополнительное приложение для настройки шрифтов, терминала и цветовой схемы
Termux-tasker - Дополнительное приложение для интеграции с Tasker
Termux-packages (Shell) - Сборка системы и первичный набор пакетов для Termux
@javatg
{kind=link}
👍9❤1👎1🔥1
Допустим, мы вставлем 8 значений в hashmap, у ключей одинаковый hashcode, но разный equals.
Все значения попадут в одну ячейку, будут выстроены в дерево.
Вопрос, как в java происходит выбор места куда новый элемент вставить в дерево, в случае коллизии? При этом ключи не comparable
В таком случае в HashMap существует утилитный метод tieBreakOrder, который формирует порядок взаимоотношения между объектами исходя из их identity hash code:
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍11❤2🔥1
В официальной документации классу Reader дано следующее определение: "BufferedReader считывает текст из символьного потока ввода, буферизируя прочитанные символы. Использование буфера призвано увеличить производительность чтения данных из потока".
Вопрос: каким образом использование буфера увеличивает производительность, по сравнению с использованием обычных ридеров?
"Обычные" (т.е. не обёрнутые в BufferedReader) ридеры за каждым чтением символов обращаются к источнику (например, файлу), что является относительно затратным по времени делом. Например, у вас есть файл, содержащий в себе довольно много символов, и вы хотите посимвольно прочитать его при помощи обычного FileReader. В таком случае каждый ваш вызов метода read(), читающий один отдельный символ, будет порождать обращение к файлу, и вы обратитесь к нему столько раз, сколько в нём имеется символов.
А BufferedReader же работает таким образом, что он обращается к источнику, считывает оттуда сразу много символов (по умолчанию 8192), занося их в определённый массив, и при следующих вызовах методов read() или readLine() символы будут читаться из этого массива, что конечно же намного быстрее.
Так что если вы захотите посимвольно прочитать текстовый файл, но уже с использованием BufferedReader, то при первом вызове метода read() сразу 8192 символа будет буферизовано, и при следующих вызовах метода символы просто будут браться из буфера.
Замерим время чтения текстового документа, состоящего примерно из ста тысяч символов, без использования BufferedReader и с ним.
Без использования BufferedReader:
long start = System.currentTimeMillis();
try(FileReader fileReader = new FileReader("sometxt.txt")) {
int i;
do {
i = fileReader.read();
} while (i != -1);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("Time: " + (System.currentTimeMillis() - start));
Результат:
Time: 428
А теперь с использованием BufferedReader:
long start = System.currentTimeMillis();
try(BufferedReader bufferedReader = new BufferedReader(new FileReader("sometxt.txt"))) {
int i;
do {
i = bufferedReader.read();
} while (i != -1);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("Time: " + (System.currentTimeMillis() - start));
Результат:
Time: 100@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍29🔥4❤2
StackOverFlowError
Эта ошибка происходит, когда переполнен стек (по-английски - stack). Если кратко, то в стеке хранятся только ссылки на объекты, которые находятся в куче. Ещё в стеке хранятся примитивы и список методов, "кто кого вызвал". Вообщем StackOverFlowError происходит при зацикливании вызова методов. Например:
public static void doSomething(){
doSomething();
}
При вызове метода doSomething() произойдёт StackOverFlowError, так как стек будет переполнен.Чтобы исправить StackOverFlowError нужно найти такое зацикливание и убрать его. На самом деле, вызов метода из самого себя использовать можно, но делать это стоит осторожно. Это будет называться рекурсия. Вот пример использования рекурсии для вычисления факториала:
public static int factorial(int number){
if(number < 0){
throw new IllegalArgumentException("Число меньше 0");
}
if(number == 0 || number == 1){
return 1;
}
return factorial(number - 1) * number;
}
В таком случае StackOverFlowError не произойдёт, так как из метода в конце-концов будет выполнен выход.В рекурсивных методах следует также проверять, что число, пришедшее в параметрах, не слишком большое. В противном случае может оказаться, что метод будет вызывать сам себя хоть и не бесконечное, но всё же достаточное количество раз, чтобы произошла ошибка StackOverFlowError.
OutOfMemoryError
Это ошибка происходит, когда переполнена куча (по-английски - heap). Если кратко, то в куче хранятся объекты. Именно объекты, а не ссылки на них. То есть OutOfMemoryError произойдёт тогда, когда в куче кончится место создавать объекты. Вот пример:
public class Test{
public static void main(String [] args){
Object[][] toManyObjects = new Object[1000000][1000000];
}
}
Этот код бует скомпилирован, но при запуске произойдёт OutOfMemoryError:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at Test.main(Test.java:5)
Ведь в массиве гигантское количество объектов, и в куче нет столько места.Конечно, никто не будет делать такие глупые ошибки. Обычно OutOfMemoryError происходит тоже при зацикливании, но не при бесконечном вызове метода, а в обычных циклах (for, while, do-while), если из таких циклов нет выхода, а в теле цикла создаются какие-либо объекты.
Примеров кодов с OutOfMemoryError масса в интернете: можете посмотреть вопросы на StackOverFlow на русском, в которых упоминается OutOfMemoryError, если вам интересно посмотреть в каких случаях такая ошибка может произойти.
Подведу итоги
▪OutOfMemoryError происходит при переполнении кучи, а StackOverFlowError - при переполнении стека;
▪StackOverFlowError происходит при бесконечном вызове метода, а OutOfMemoryError - при зацикливании создания объектов;
▪И того, и другое нужно исправить: найти зацикливание и устранить его.
Ссылки
▪Статья на хабре про память в java
▪Ещё одна статья на хабре про память в java
▪Пост на английском StackOverFlow
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍31❤4🔥2
Дан класс Film, у которого поле типа LocalDate должно быть не раньше 28 декабря 1895 года. Используем библиотеку javax.validation.constraints, где представлены
@Past, @Future, @FutureOrPresent, @PastOrPresent.
Для этой цели создадим свою кастомную аннотацию и валидатор. Пример статьи на эту тему
Класс аннотации
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = MinimumDateValidator.class)
@Past
public @interface MinimumDate {
String message() default "Date must not be before {value}";
Class<?>[] groups() default {};
Class<?>[] payload() default {};
String value() default "1895-12-28";
}
Кастомный класс валидатора, который будет эту аннотацию обрабатывать
public class MinimumDateValidator implements ConstraintValidator<MinimumDate, LocalDate> {
private LocalDate minimumDate;
@Override
public void initialize(MinimumDate constraintAnnotation) {
minimumDate = LocalDate.parse(constraintAnnotation.value());
}
@Override
public boolean isValid(LocalDate value, ConstraintValidatorContext context) {
return value == null || !value.isBefore(minimumDate);
}
}Для таких целей придется создать свою кастомную аннотацию и валидатор. Пример статьи на эту тему
Класс аннотации
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = MinimumDateValidator.class)
@Past
public @interface MinimumDate {
String message() default "Date must not be before {value}";
Class<?>[] groups() default {};
Class<?>[] payload() default {};
String value() default "1895-12-28";
}
Кастомный класс валидатора, который будет эту аннотацию обрабатывать
public class MinimumDateValidator implements ConstraintValidator<MinimumDate, LocalDate> {
private LocalDate minimumDate;
@Override
public void initialize(MinimumDate constraintAnnotation) {
minimumDate = LocalDate.parse(constraintAnnotation.value());
}
@Override
public boolean isValid(LocalDate value, ConstraintValidatorContext context) {
return value == null || !value.isBefore(minimumDate);
}
}Пример использования
public class Person {
@MinimumDate
private LocalDate birthDate;
}
@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍21🔥4🤯2❤1
Есть метод, который группирует элементы коллекции из нескольким полям.
public void test() {
List<Item> itemsList = ...//Чтение из XML;
Map<List<Object>, List<Item>> groupBy =
itemsList.stream().collect(Collectors.groupingBy(
i -> Arrays.asList(i.id, i.city, i.order_status)));
for (Map.Entry<List<Object>, List<Item>> t : groupBy.entrySet()) {
System.out.println(t.getKey());
for (Item item : t.getValue()) {
System.out.println(" " + item);
}
}
}Как сделать такое же без Stream API?
Для этого можно создать мапу с явным указанием типа ключа и значений, в цикле проходишь по списку и добавляешь элементы в мапу при помощи
Map::computeIfAbsent -- этот метод при необходимости создаёт новое или возвращает существующее значение-список, для которого можно сразу же вызвать метод List:add.При этом лучше использовать LinkedHashMap, чтобы порядок элементов в ней был стабильный (HashMap порядка не гарантирует).
public static Map<List<Object>, List<Item>> groupBy(List<Item> list) {
Map<List<Object>, List<Item>> map = new LinkedHashMap<>();
for (Item item : list) {
List<Object> key = Arrays.asList(item.getId(), item.getCity(), item.getOrderStatus());
map.computeIfAbsent(key, k -> new ArrayList<>()).add(item);
}
return map;
}
Это достаточно просто сделать при помощи кортежей record, официально поддерживаемых с Java 16, или Lombok-аннотаций
@Data / @AllArgsConstructor.enum OrderStatus {NEW, PROCESSING, COMPLETED, CANCELED};
// определены конструктор, геттеры без префикса `get`, hashCode / equals, toString
record MyKey(long id, String city, OrderStatus status) {
public MyKey(Item item) {
this(item.getId(), item.getCity(), item.getOrderStatus());
}
}
public static Map<MyKey, List<Item>> groupBy(List<Item> list) {
Map<MyKey, List<Item>> map = new LinkedHashMap<>();
list.forEach(item -> map
.computeIfAbsent(new MyKey(item), k -> new ArrayList<>())
.add(item)
);
// отладочный вывод
map.forEach((key, val) -> {
System.out.println(key);
val.forEach(item -> System.out.println("\t" + item));
});
return map;
}
При желании создание такой группировки можно параметризовать для любого ключа, если передавать некую функцию-конвертор Function<Item, Key>, в последнем примере такой функцией был конструктор кортежа MyKey(Item item). Например, для генерации ключа-списка можно было бы определить отдельный фабричный метод:
// MyClass
public static List<Object> keyIdCityStatus(Item item) {
return Arrays.asList(item.getId(), item.getCity(), item.getOrderStatus());
}
Параметризованный метод выглядит так:
public static<K> Map<K, List<Item>> groupBy(Function<Item, K> keyBuilder, List<Item> list) {
Map<K, List<Item>> map = new LinkedHashMap<>();
list.forEach(item -> map
.computeIfAbsent(keyBuilder.apply(item), k -> new ArrayList<>())
.add(item)
);
return map;
}
Соответственно вызывать его можно для любого ключа:
// ссылка на фабричный метод MyClass::keyIdCityStatus
Map<List<Object>, List<Item>> keyListMap = groupBy(MyClass::keyIdCityStatus, list);
// ссылка на конструктор MyKey::new
Map<MyKey, List<Item>> keyRecordMap = groupBy(MyKey::new, list);@javatg
Please open Telegram to view this post
VIEW IN TELEGRAM
👍14🔥2❤1