
Что происходит внутри TreeMap.put()?
Недавно мы в деталях рассматривали, какие процессы происходят при добавлении элемента в
Подобно нодам в хэш-таблице, внутренняя структура дерева строится из объектов внутреннего класса узла –
Сама структура представляет из себя красно-чёрное дерево относительно ключей. Не будем здесь углубляться в детали его реализации. О нем важно знать два факта:
1. Это бинарное дерево поиска. Значит, каждый новый элемент начинает искать свое место в дереве, сравниваясь с узлами начиная с корневого. Меньшие элементы движутся влево, большие – вправо. Для этого и требуется наличие метода
2. Это самобалансирующееся дерево. Если какая-то ветка начинает становиться слишком длинной (а её эффективность вырождаться в эффективность связного списка), происходит балансировка. В результате этой операции правило из пунтка 1 остается в силе, но нагрузка на ветки перераспределяется. Самое длинное поддерево становится выше самого короткого максимум на один элемент.
Чтобы осознать процесс построения RB-дерева, есть интерактивное демо.
#Коллекции
@javatg
Недавно мы в деталях рассматривали, какие процессы происходят при добавлении элемента в
HashMap. Теперь поговорим о TreeMap. Здесь не так много тонкостей, как в хэш-таблице.TreeMap требует либо задать порядок ключей вручную (передать в конструктор Comparator), либо чтобы они имели собственный естественный порядок (были Comparable).Подобно нодам в хэш-таблице, внутренняя структура дерева строится из объектов внутреннего класса узла –
Entry. В каждом узле хранится информация о данных (пара key-value), и о положении в структуре (ссылки на родительский узел, левую и правую ветви).Сама структура представляет из себя красно-чёрное дерево относительно ключей. Не будем здесь углубляться в детали его реализации. О нем важно знать два факта:
1. Это бинарное дерево поиска. Значит, каждый новый элемент начинает искать свое место в дереве, сравниваясь с узлами начиная с корневого. Меньшие элементы движутся влево, большие – вправо. Для этого и требуется наличие метода
compare. Дойдя до конца, пара ключ-значение «повисает» новым узлом.2. Это самобалансирующееся дерево. Если какая-то ветка начинает становиться слишком длинной (а её эффективность вырождаться в эффективность связного списка), происходит балансировка. В результате этой операции правило из пунтка 1 остается в силе, но нагрузка на ветки перераспределяется. Самое длинное поддерево становится выше самого короткого максимум на один элемент.
Чтобы осознать процесс построения RB-дерева, есть интерактивное демо.
#Коллекции
@javatg
{kind=link}
👍21
Какие задачи решает Spring Data?
Это проект, который упрощает работу с системами доступа к данным: реляционными и нереляционными базами данных, map-reduce фреймворками и облачными хранилищами. Центральная концепция проекта – репозитории из предметно-ориентированного дизайна (Domain-driven design, DDD).
Spring Data состоит из множества отдельных библиотек для разных случаев жизни. Вот самые популярные из них:
• Spring Data JPA – адаптер для реализаций Java Persistence API, таких как Hibernate.
• Spring Data JDBC – более простой и ограниченный чем JPA адаптер для JDBC-драйверов.
• Spring Data REST – создание готовых hypermedia-driven RESTful сервисов на основе репозиториев.
• Spring Data KeyValue – работа с хранилищами типа ключ-значение.
• Библиотеки поддержки конкретных реализаций хранилищ: MongoDB, Redis, Cassandra, LDAP, и других.
#Spring
@javatg
Это проект, который упрощает работу с системами доступа к данным: реляционными и нереляционными базами данных, map-reduce фреймворками и облачными хранилищами. Центральная концепция проекта – репозитории из предметно-ориентированного дизайна (Domain-driven design, DDD).
Spring Data состоит из множества отдельных библиотек для разных случаев жизни. Вот самые популярные из них:
• Spring Data JPA – адаптер для реализаций Java Persistence API, таких как Hibernate.
• Spring Data JDBC – более простой и ограниченный чем JPA адаптер для JDBC-драйверов.
• Spring Data REST – создание готовых hypermedia-driven RESTful сервисов на основе репозиториев.
• Spring Data KeyValue – работа с хранилищами типа ключ-значение.
• Библиотеки поддержки конкретных реализаций хранилищ: MongoDB, Redis, Cassandra, LDAP, и других.
#Spring
@javatg
{kind=link}
👍12🔥4❤1
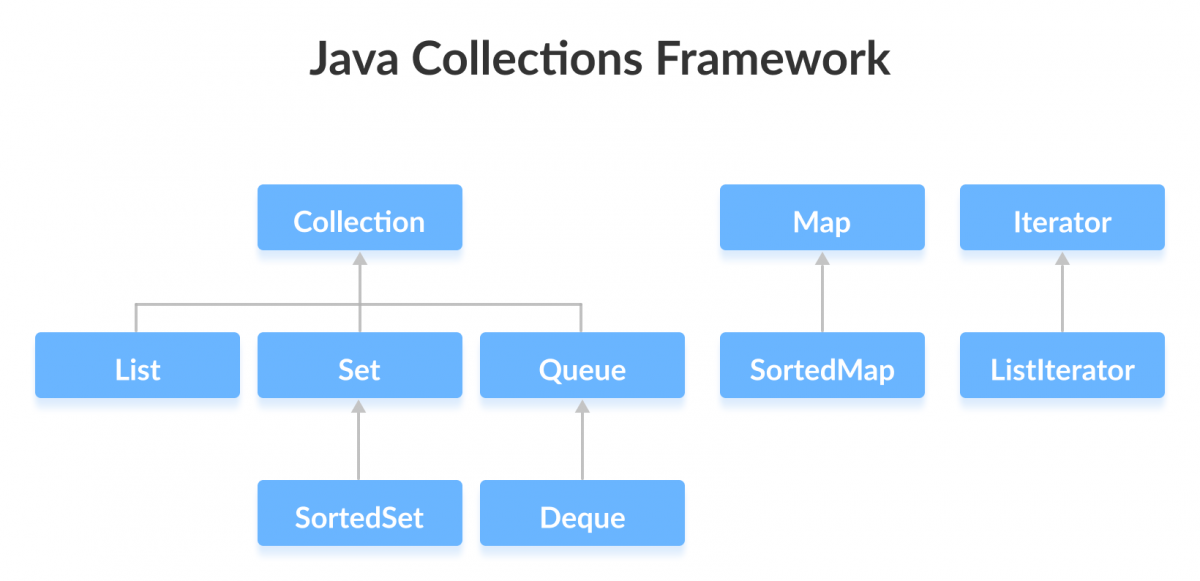
Можно ли хранить null в стандартных коллекциях?
Все интерфейсы Collections Framework позволяют своим реализациям самостоятельно решать, поддерживать ли null-значения. Если реализация не может принять
Большинство списков (
Unmodifiable Maps не допускают null-ов совсем. Обычные изменяемые мапы обычно не испытывают трудности со значениями null. А вот с ключами дело обстоит интереснее.
Иногда этот вопрос дается как задача с подвохом про
Для значений Set-ов действуют те же правила, что для ключей лежащих в основе их Map-ов.
#Коллекции
@javatg
Все интерфейсы Collections Framework позволяют своим реализациям самостоятельно решать, поддерживать ли null-значения. Если реализация не может принять
null, она выбрасывает NullPointerException или ClassCastException.Большинство списков (
LinkedList, ArrayList) принимают null без проблем. Большинство очередей (Queue и Deque) не хранят null – возвращая из читающего метода null они сообщают пользователю о пустоте коллекции.Unmodifiable Maps не допускают null-ов совсем. Обычные изменяемые мапы обычно не испытывают трудности со значениями null. А вот с ключами дело обстоит интереснее.
HashMap не может посчитать hash-сумму от null. Но вместо этого для таких ключей просто используется бакет номер 0.Иногда этот вопрос дается как задача с подвохом про
TreeMap. Nullability её ключей зависит от готовности к этому компаратора. Натуральный порядок (который работает для Comparable ключей) не поддерживает null. Раньше в реализации был баг, который позволял положить значение по ключу null в корень дерева без выброса исключения.Для значений Set-ов действуют те же правила, что для ключей лежащих в основе их Map-ов.
#Коллекции
@javatg
{kind=link}
👍14❤1
Как работают фильтры сервлетов?
Filter Chain – типичный пример реализации паттерна Chain of responsibility. Каждый фильтр может модифицировать запрос/ответ, и либо отправить на обработку следующему фильтру, либо заворачивать обратно. В фильтрах удобно выполнять некий общий код обработки запросов: отклонение неавторизованных обращений, логгирование, обогащение запроса/ответа данными из контекста.
Фильтр состоит из трех методов:
Подробнее можно почитать тут
#JavaEE
@javatg
Servlet содержит саму бизнес-логику обработки запросов. Реализации интерфейса javax.servlet.Filter выстраиваются в цепочку, через которую проходит запрос по пути в сервлет, и ответ на него по пути обратно к пользователю.Filter Chain – типичный пример реализации паттерна Chain of responsibility. Каждый фильтр может модифицировать запрос/ответ, и либо отправить на обработку следующему фильтру, либо заворачивать обратно. В фильтрах удобно выполнять некий общий код обработки запросов: отклонение неавторизованных обращений, логгирование, обогащение запроса/ответа данными из контекста.
Фильтр состоит из трех методов:
init, doFilter и destroy. doFilter – основная реализация фильтрации, он вызывается для каждого запроса. Инициализация и уничтожение вызываются строго по одному разу. Кроме того, сервлет-контейнер гарантирует, что их вызовы не будут пересекаться: doFilter не начнет работать до конца выполнения init, и закончит до начала destroy. Подробнее можно почитать тут
#JavaEE
@javatg
Wikipedia
Цепочка обязанностей
поведенческий шаблон проектирования для организации в системе уровней ответственности
👍9❤1
Когда используется StampedLock?
Во-первых, если блокировка
В
Не смотря на похожесть,
Итого, блокировка на штампах решает те же задачи, что ReadWriteLock, но дает больше возможностей и лучшую производительность.
Статья
#Многопоточность
@javatg
StampedLock – примитив синхронизации, добавленный в Java с версии 8. Общий принцип его работы точно такой же, как у ReadWriteLock: захват неэксклюзивной блокировки (на чтение), и эксклюзивной (на запись). Но есть у этих классов ряд различий в деталях.Во-первых, если блокировка
ReadWriteLock возвращает объекты типа Lock, то StampedLock возвращает числа типа long, которые и называется «штампами». Штамп служит идентификатором лока, он передается параметром в методы по работе с ранее захваченной блокировкой чтения или записи. Специальный штамп 0 означает неудавшийся захват.StampedLock в отличие от ReentrantReadWriteLock – не реентрант. Это накладывает бóльшую ответственность на программиста: можно устроить дедлок на одном потоке.В
StampedLock расширена функциональность. Новые методы с префиксом try* не висят в ожидании. Методы tryOptimistic* реализуют оптимистичную блокировку. Методы tryConvert* дают возможность изменять «уровень» заблокированности: можно попытаться превратить readLock во writeLock, и наоборот.Не смотря на похожесть,
StampedLock не наследуется от ReadWriteLock. Но для совместимости в нём предусмотрены методы-адаптеры asReadWriteLock, asReadLock и asWriteLock.Итого, блокировка на штампах решает те же задачи, что ReadWriteLock, но дает больше возможностей и лучшую производительность.
Статья
#Многопоточность
@javatg
{kind=link}
👍8❤1
Геймификация позволяет добавлять элементы игры куда угодно — в работу, учебу, повседневную жизнь 🎮 Как эта техника делает рутинные задачи интереснее? Почему она полезна в школах и как с помощью геймификации магазины привлекают клиентов? Об этом — в новом эпизоде подкаста Газпромбанка «ZIP. Архив техногенного мира».
Слушайте и делитесь
Слушайте и делитесь
Сравните репозитории Spring Data
Основная часть работы в Spring Data строится вокруг интерфейса
CrudRepository – базовый набор операций над сущностями: создание, чтение, изменение и удаление (CRUD).
PagingAndSortingRepository – добавляет к CRUD возможность постраничной загрузки данных с определенной сортировкой.
JpaRepository – расширение
MongoRepository – расширение
Вспомогательные методы, специфичные для конкретной модели данных, добавляются в пользовательские интерфейсы-наследники. Основываясь на именах добавляемых методов, фреймворк сам создаёт их реализацию.
#Spring
@javatg
Основная часть работы в Spring Data строится вокруг интерфейса
Repository. Это маркерный интерфейс. От него наследуются интерфейсы-специализации, которые уже содержат методы для работы с сущностями базы данных. Все эти интерфейсы параметризуются двумя типами: самой сущности и её идентификатора.CrudRepository – базовый набор операций над сущностями: создание, чтение, изменение и удаление (CRUD).
PagingAndSortingRepository – добавляет к CRUD возможность постраничной загрузки данных с определенной сортировкой.
JpaRepository – расширение
PagingAndSortingRepository, полноценно реализующее Java Persistence API. Добавляет ряд методов, таких как например flush и deleteInBatch.MongoRepository – расширение
PagingAndSortingRepository, специфичное для MongoDB.Вспомогательные методы, специфичные для конкретной модели данных, добавляются в пользовательские интерфейсы-наследники. Основываясь на именах добавляемых методов, фреймворк сам создаёт их реализацию.
#Spring
@javatg
{kind=link}
👍13😁1
Сколько вариантов вывода может быть?
#concurrency #java
class A {
int a;
int b;
void m1() {
a++;
b++;
}
void m2() {
System.out.println(b);
System.out.println(a);
}
}
// пример вывода: b=1 a=0
Методы m1 и m2 запускаются в разных потоках, одновременно, один раз каждый
Ответ:4
@javatg
#concurrency #java
class A {
int a;
int b;
void m1() {
a++;
b++;
}
void m2() {
System.out.println(b);
System.out.println(a);
}
}
// пример вывода: b=1 a=0
Методы m1 и m2 запускаются в разных потоках, одновременно, один раз каждый
Ответ:
👍17😁2❤1🥰1
Что хранится в файле манифеста?
В JAR архиве можно найти файл
Манифест – текстовый файл, который состоит из заголовков, строчек вида
Вот некоторые из часто используемых заголовков:
• Информация об архиве: Manifest-Version, Created-By, Multi-Release, Built-By
• Main-class – точка входа приложения
• Classpath приложения
• Информация об экстеншне (Specification и Implementation, deprecated)
• Заголовки OSGI бандла
• Типы и хэши файлов архива (особенно применимо в Android приложениях)
Полный список стандартных заголовков можно почитать в документации.
#JVM
@javatg
В JAR архиве можно найти файл
META-INF/MANIFEST.MF. Это манифест архива – хранилище его метаинформации. Манифест обычно добавляется той же утилитой, которой собирается jar-файл: maven-jar-plugin, команда JDK jar.Манифест – текстовый файл, который состоит из заголовков, строчек вида
ключ: значение. Заголовки разделены на секции. Файл начинается с главной секции, описывающей метаинформацию всего архива. Следом, отделенные пустыми строками, идут секции для отдельных пакетов и файлов. В них могут переопределяться общие заголовки. JVM игнорирует неизвестные ей заголовки, что позволяет сторонним утилитам хранить в манифесте свою специфичную метаинформацию.Вот некоторые из часто используемых заголовков:
• Информация об архиве: Manifest-Version, Created-By, Multi-Release, Built-By
• Main-class – точка входа приложения
• Classpath приложения
• Информация об экстеншне (Specification и Implementation, deprecated)
• Заголовки OSGI бандла
• Типы и хэши файлов архива (особенно применимо в Android приложениях)
Полный список стандартных заголовков можно почитать в документации.
#JVM
@javatg
{kind=link}
👍7
Какие интерфейсы предоставляют возможность хранить объекты в виде пары "ключ-значение"?
Anonymous Quiz
4%
java.util.List
6%
java.util.Set
1%
java.util.SortedSet
81%
java.util.Map
3%
Все варианты неверные
5%
Узнать ответ
👍16❤1🥰1
Как приложению ограничить доступ к файлу?
В целях безопасности, весь доступ приложения к определенным частям кода и ресурсам может быть ограничен. Решения о доступе к, например, Reflection API, или к файлу принимаются менеджером безопасности.
Внутри менеджера представлен набор методов
Экземпляр класса
Менеджер безопасности изначально был нужен для ограничения апплетов – они выполнялись в браузере пользователя и не должны были получить доступ к локальным пользовательским данным. Сейчас технология апплетов устарела, но SecurityManager остается всё таким же актуальным.
#Безопасность
Подробнее
@javatg
В целях безопасности, весь доступ приложения к определенным частям кода и ресурсам может быть ограничен. Решения о доступе к, например, Reflection API, или к файлу принимаются менеджером безопасности.
Внутри менеджера представлен набор методов
check*(), которые делегируют выполнение основному методу checkPermission(). Сам доступ, права на который нужно проверить, представляется классом java.security.Permission. Так, доступ к файлу на чтение проверяет метод checkRead. Он передает в checkPermission объект FilePermission с указанным именем файла.Экземпляр класса
SecurityManager, который реализует нужную логику ограничения доступа, можно установить программно методом System.setSecurityManager, или на старте приложения флагом -Djava.security.manager. По умолчанию менеджер не установлен.Менеджер безопасности изначально был нужен для ограничения апплетов – они выполнялись в браузере пользователя и не должны были получить доступ к локальным пользовательским данным. Сейчас технология апплетов устарела, но SecurityManager остается всё таким же актуальным.
#Безопасность
Подробнее
@javatg
👍11
👍24👎4👏1
Для чего нужно ключевое слово super?
Как и многие другие ключевые слова,
1. Задать нижнюю границу generic-типа:
2. Обратиться к члену класса-родителя, который перекрыт (shadowed) членами наследника или локальными переменными:
3. Вызвать в конструкторе конструктор родителя:
4. В случае неопределенности, уточнить родительский тип (на картинке)
#Язык
@javatg
Как и многие другие ключевые слова,
super имеет несколько разных значений в зависимости от контекста:1. Задать нижнюю границу generic-типа:
Consumer<? super Number>2. Обратиться к члену класса-родителя, который перекрыт (shadowed) членами наследника или локальными переменными:
int foo = super.foo3. Вызвать в конструкторе конструктор родителя:
SubClass() { super("subclass param"); }4. В случае неопределенности, уточнить родительский тип (на картинке)
#Язык
@javatg
{kind=link}
👍20❤3🔥1🥰1
Что выведет данный код?
Anonymous Quiz
8%
Infinity NaN
6%
Infinity Infinity
35%
Error
12%
NaN NaN
21%
NaN Infinity
18%
Узнать ответ
👍18